CONTENTS
- LeetCode 86. 分隔链表(中等)
- LeetCode 87. 扰乱字符串(困难)
- LeetCode 88. 合并两个有序数组(简单)
- LeetCode 89. 格雷编码(中等)
- LeetCode 90. 子集 II(中等)
LeetCode 86. 分隔链表(中等)
【题目描述】
给你一个链表的头节点 head 和一个特定值 x x x,请你对链表进行分隔,使得所有小于 x x x 的节点都出现在大于或等于 x x x 的节点之前。
你应当保留两个分区中每个节点的初始相对位置。
【示例 1】
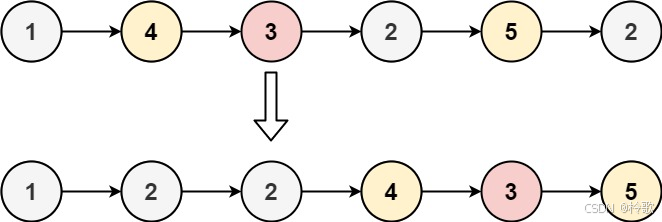
输入:head = [1,4,3,2,5,2], x = 3
输出:[1,2,2,4,3,5]
【示例 2】
输入:head = [2,1], x = 2
输出:[1,2]
【提示】
链表中节点的数目在范围 [ 0 , 200 ] [0, 200] [0,200] 内
− 100 < = N o d e . v a l < = 100 -100 <= Node.val <= 100 −100<=Node.val<=100
− 200 < = x < = 200 -200 <= x <= 200 −200<=x<=200
【分析】
可以创建两个新链表分别表示小于 x x x 的节点与大于等于 x x x 的节点,然后遍历一遍原链表将每个节点插入到对应的新链表中,最后将大于等于 x x x 的那个链表接在小于 x x x 的链表后面即可。
也可以在原链表上原地操作,这样空间开销会少一点,画个图更好理解,按顺序遍历每个节点,先找到大于等于 x x x 的前一个节点停下来,记为 p,然后从 p 开始用另一个指针继续向后扫描,找到小于 x x x 的前一个结点停下来,记为 q:

这时候 q->next 需要和 p->next 交换位置,也就是进行以下操作:
- 将
q->next记为v; q->next = v->next;v->next = p->next;p->next = v。
交换完成后将 p 向后移动到下一个节点重复前面的判断即可。
【代码】
【创建新链表】
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* partition(ListNode* head, int x) {auto leftDummy = new ListNode(-1), curLeft = leftDummy;auto rightDummy = new ListNode(-1), curRight = rightDummy;while (head) {if (head->val < x) curLeft = curLeft->next = head;else curRight = curRight->next = head;head = head->next;}curRight->next = nullptr; // 记着将右半段链表的末尾设为空,因为末尾节点在原链表未必也是末尾curLeft->next = rightDummy->next; // 将右半段链表接到左半段的末尾return leftDummy->next;}
};
【原地操作】
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* partition(ListNode* head, int x) {ListNode* dummy = new ListNode(-1, head);for (ListNode* p = dummy; p; p = p->next) {while (p->next && p->next->val < x) p = p->next;ListNode* q = p;while (q->next && q->next->val >= x) q = q->next;if (q->next) {ListNode* v = q->next;q->next = v->next;v->next = p->next;p->next = v;}}return dummy->next;}
};
LeetCode 87. 扰乱字符串(困难)
【题目描述】
使用下面描述的算法可以扰乱字符串 s 得到字符串 t:
- 如果字符串的长度为 1,算法停止。
- 如果字符串的长度大于 1,执行下述步骤:
- 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
s,则可以将其分成两个子字符串x和y,且满足s = x + y。 - 随机决定是要「交换两个子字符串」还是要「保持这两个子字符串的顺序不变」。即,在执行这一步骤之后,
s可能是s = x + y或者s = y + x。 - 在
x和y这两个子字符串上继续从步骤 1 开始递归执行此算法。
- 在一个随机下标处将字符串分割成两个非空的子字符串。即,如果已知字符串
给你两个长度相等的字符串 s1 和 s2,判断 s2 是否是 s1 的扰乱字符串。如果是,返回 true;否则,返回 false。
【示例 1】
输入:s1 = "great", s2 = "rgeat"
输出:true
解释:s1 上可能发生的一种情形是:
"great" --> "gr/eat" // 在一个随机下标处分割得到两个子字符串
"gr/eat" --> "gr/eat" // 随机决定:「保持这两个子字符串的顺序不变」
"gr/eat" --> "g/r / e/at" // 在子字符串上递归执行此算法。两个子字符串分别在随机下标处进行一轮分割
"g/r / e/at" --> "r/g / e/at" // 随机决定:第一组「交换两个子字符串」,第二组「保持这两个子字符串的顺序不变」
"r/g / e/at" --> "r/g / e/ a/t" // 继续递归执行此算法,将 "at" 分割得到 "a/t"
"r/g / e/ a/t" --> "r/g / e/ a/t" // 随机决定:「保持这两个子字符串的顺序不变」
算法终止,结果字符串和 s2 相同,都是 "rgeat"
这是一种能够扰乱 s1 得到 s2 的情形,可以认为 s2 是 s1 的扰乱字符串,返回 true
【示例 2】
输入:s1 = "abcde", s2 = "caebd"
输出:false
【示例 3】
输入:s1 = "a", s2 = "a"
输出:true
【提示】
s 1. l e n g t h = = s 2. l e n g t h s1.length == s2.length s1.length==s2.length
1 < = s 1. l e n g t h < = 30 1 <= s1.length <= 30 1<=s1.length<=30
s1 和 s2 由小写英文字母组成
【分析】
【递归解法】
如果当前两个字符串已经相等,说明 s1 可以通过扰乱得到 s2,返回 true;如果 s1 中各个字符的数量与 s2 不匹配,那么一定无法通过扰乱得到 s2(剪枝),可以将两个字符串排序后判断是否相等即可。
如果当前两个字符串不相等,但是字符数量匹配,那么可能就需要进行分割和交换操作,首先枚举 s1 分割点的位置,分割后的两个区间不能为空,因此我们直接枚举左子区间的元素数量 i i i,那么右子区间的元素数量就为 n − i n - i n−i。
分割后还要枚举是否交换,也就是有两种可能的情况(这部分很重要):
- 无需交换:说明
s1的前 i i i 个字符通过干扰能够与s2的前 i i i 个字符相等,s1的后 n − i n - i n−i 个字符通过干扰能够与s2的后 n − i n - i n−i 个字符相等; - 需要交换:说明
s1的前 i i i 个字符通过干扰能够与s2的后 i i i 个字符相等,s1的后 n − i n - i n−i 个字符通过干扰能够与s2的前 n − i n - i n−i 个字符相等。
画个图来理解一下,下面这两种情况都代表 s1 通过干扰能转化为 s2:

- 对于不交换的情况,如果
s1的前 i i i 个字符"hel"通过某些干扰(具体怎么变不用管,因为后续会分别递归判断)能变为s2的前 i i i 个字符“elh”,且两个字符串的后 n − i n - i n−i 个字符同理也能通过干扰转化,那么对于当前分析的长度为 n n n 的情况返回就应该是true。此处很明显子串可以这么转化:"h/el -> el/h"、"lowo/rld -> rld/lowo"。 - 对于交换的情况分析是一样的,子串可能的转化方式与前一种情况一样,区别就是两个子串的位置交换过了。
分析一下递归解法的时间复杂度,假设字符串长度为 n n n 时代码的执行次数为 a n a_n an,对于长度为 n n n 的字符串,有四个递归式,每个递归式都相当于遍历了不同长度(从 1 ∼ n − 1 1\sim n - 1 1∼n−1)的子串,因此时间复杂度 a n a_n an 为:
a n = 4 ( a 1 + a 2 + ⋯ + a n − 1 ) a n − 1 = 4 ( a 1 + a 2 + ⋯ + a n − 2 ) a n − a n − 1 = 4 a n − 1 ⇒ a n = 5 a n − 1 = 5 2 a n − 2 = 5 3 a n − 3 = 5 n a_n = 4(a_1 + a_2 + \dots + a_{n - 1}) \\ a_{n - 1} = 4(a_1 + a_2 + \dots + a_{n - 2}) \\ a_n - a_{n - 1} = 4a_{n - 1}\Rightarrow a_n = 5a_{n - 1} = 5^2a_{n - 2} = 5^3a_{n - 3} = 5^n an=4(a1+a2+⋯+an−1)an−1=4(a1+a2+⋯+an−2)an−an−1=4an−1⇒an=5an−1=52an−2=53an−3=5n
这个时间复杂度会超时,但是确实是一种很妙的思路,接下来讲一下更高效的解法。
【动态规划解法】
每次分割后两个子串各自都是连续的,且这两个子串直接相互独立不会有任何关联,这就隐约引导我们往区间 DP 上考虑。
- 状态表示: f [ i ] [ j ] [ k ] f[i][j][k] f[i][j][k] 表示将
s1[i, i + k - 1]转化成s2[j, j + k - 1]的所有方案的集合是否非空( k = 1 , 2 , … , n k = 1, 2, \dots, n k=1,2,…,n)。 - 状态计算
- 集合划分:枚举
s1的分割点,记左子区间的长度为 u ( u = 1 , … , k − 1 ) u(u = 1, \dots , k - 1) u(u=1,…,k−1),则右子区间的长度为 k − u k - u k−u; - 如果没有进行交换操作,那么
s1的前 u u u 个字符能转化成s2的前 u u u 个字符,s1的后 k − u k - u k−u 个字符能转化成s2的后 k − u k - u k−u 个字符(和之前递归解法类似),前者的表示方式就是 f [ i ] [ j ] [ u ] f[i][j][u] f[i][j][u],后者的表示方式就是 f [ i + u ] [ j + u ] [ k − u ] f[i + u][j + u][k - u] f[i+u][j+u][k−u],因此状态转移方程为:f[i][j][k] = f[i][j][u] && f[i + u][j + u][k - u]; - 如果进行了交换操作,同理可知状态转移方程为:
f[i][j][k] = f[i][j + k - u][u] && f[i + u][j][k - u]; - 因此总的状态转移方程为:
f[i][j][k] |= f[i][j][u] && f[i + u][j + u][k - u] || f[i][j + k - u][u] && f[i + u][j][k - u]。
- 集合划分:枚举
需要枚举的状态数量为 n 3 n^3 n3,转移数量为 n n n,因此时间复杂度为 O ( n 4 ) O(n^4) O(n4)。当 f [ i ] [ j ] [ k ] f[i][j][k] f[i][j][k] 为 true 时可以跳过当前枚举分割点的循环稍微优化一点速度,不过影响不大。
注意代码中我们不能写 f[i][j][k] |= ...,因为我们用的数组是 vector<bool>,这是一个特化模板,它并不是直接存储 bool 类型的值,而是通过位(bit)来存储,以节省空间。因此,当你访问 vector<bool> 中的元素时,返回的并不是一个 bool 类型的引用,而是一个代理对象 std::_Bit_reference,将 bool 类型的变量赋值给 std::_Bit_reference 是没有问题的,因为 std::_Bit_reference 重载了赋值运算符,但使用按位或赋值运算符 |= 时,情况有所不同,因为 std::_Bit_reference 并没有重载这个运算符。
【代码】
【递归代码】
class Solution {
public:bool isScramble(string s1, string s2) {if (s1 == s2) return true;string t1 = s1, t2 = s2;sort(t1.begin(), t1.end());sort(t2.begin(), t2.end());if (t1 != t2) return false;int n = s1.size();for (int i = 1; i < n; i++) {// 不交换if (isScramble(s1.substr(0, i), s2.substr(0, i)) &&isScramble(s1.substr(i), s2.substr(i))) return true;// 交换if (isScramble(s1.substr(0, i), s2.substr(n - i)) &&isScramble(s1.substr(i), s2.substr(0, n - i))) return true;}return false;}
};
【动态规划代码】
class Solution {
public:bool isScramble(string s1, string s2) {int n = s1.size();vector<vector<vector<bool>>> f(n, vector(n, vector<bool>(n + 1)));for (int k = 1; k <= n; k++)for (int i = 0; i + k - 1 < n; i++)for (int j = 0; j + k - 1 < n; j++)if (k == 1) f[i][j][k] = s1[i] == s2[j]; // k 为 1 时就不用分裂了,如果 s1[i] 与 s2[j] 相等那么 f 就为 trueelse for (int u = 1; u < k; u++)f[i][j][k] = f[i][j][k] || f[i][j][u] && f[i + u][j + u][k - u] ||f[i][j + k - u][u] && f[i + u][j][k - u];return f[0][0][n];}
};
LeetCode 88. 合并两个有序数组(简单)
【题目描述】
给你两个按非递减顺序排列的整数数组 nums1 和 nums2,另有两个整数 m m m 和 n n n,分别表示 nums1 和 nums2 中的元素数目。
请你合并 nums2 到 nums1 中,使合并后的数组同样按非递减顺序排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n m + n m+n,其中前 m m m 个元素表示应合并的元素,后 n n n 个元素为 0,应忽略。nums2 的长度为 n n n。
【示例 1】
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
【示例 2】
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。
【示例 3】
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
【提示】
n u m s 1. l e n g t h = = m + n nums1.length == m + n nums1.length==m+n
n u m s 2. l e n g t h = = n nums2.length == n nums2.length==n
0 < = m , n < = 200 0 <= m, n <= 200 0<=m,n<=200
1 < = m + n < = 200 1 <= m + n <= 200 1<=m+n<=200
− 1 0 9 < = n u m s 1 [ i ] , n u m s 2 [ j ] < = 1 0 9 -10^9 <= nums1[i], nums2[j] <= 10^9 −109<=nums1[i],nums2[j]<=109
【分析】
归并排序的合并思路,由于 nums1 就是最终整段数组的长度,因此不用开一个额外的数组进行合并,而是从大到小倒序遍历两个数组,将大的数逐个填放到 nums1 的末尾,这样就不会覆盖 nums1 原本的数,而且两个数组都是有序的,如果 nums2 已经遍历完了,那么 nums1 就不用继续遍历了,因为 nums1 前面的数也已经都是有序的了。
【代码】
class Solution {
public:void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {int i = m - 1, j = n - 1, k = m + n - 1;while (i >= 0 && j >= 0) {if (nums1[i] > nums2[j]) nums1[k--] = nums1[i--];else nums1[k--] = nums2[j--];}while (j >= 0) nums1[k--] = nums2[j--]; // nums1 没遍历完不影响,只要确保 nums2 的元素都合并过来了就行}
};
LeetCode 89. 格雷编码(中等)
【题目描述】
n n n 位格雷码序列是一个由 2 n 2^n 2n 个整数组成的序列,其中:
- 每个整数都在范围 [ 0 , 2 n − 1 ] [0, 2n - 1] [0,2n−1] 内(含 0 和 2 n − 1 2n - 1 2n−1);
- 第一个整数是 0;
- 一个整数在序列中出现不超过一次;
- 每对相邻整数的二进制表示恰好一位不同,且第一个和最后一个整数的二进制表示恰好一位不同。
给你一个整数 n n n,返回任一有效的 n n n 位格雷码序列。
【示例 1】
输入:n = 2
输出:[0,1,3,2]
解释:
[0,1,3,2] 的二进制表示是 [00,01,11,10] 。
- 00 和 01 有一位不同
- 01 和 11 有一位不同
- 11 和 10 有一位不同
- 10 和 00 有一位不同
[0,2,3,1] 也是一个有效的格雷码序列,其二进制表示是 [00,10,11,01] 。
- 00 和 10 有一位不同
- 10 和 11 有一位不同
- 11 和 01 有一位不同
- 01 和 00 有一位不同
【示例 2】
输入:n = 1
输出:[0,1]
【提示】
1 < = n < = 16 1 <= n <= 16 1<=n<=16
【分析】
格雷码生成具有规律,如果自己想还是比较具有跳跃性,可以当作一个知识点记下来。
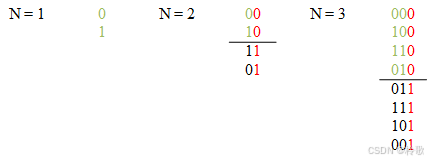
首先从 n = 1 n = 1 n=1 开始递归生成,只有一位的时候就两种情况:0 和 1,当 n = 2 n = 2 n=2 时在上一种情况的基础上再复制一份并翻转顺序,然后在原始的编码末尾补 0,在翻转后的编码末尾补 1,之后每一轮的操作都一样。
为什么这样做能保证正确性?
- 未翻转的区间中相邻的编码已经确定只有一位不同,因此末尾都补 0 也一样满足只有一位不同;
- 翻转后的区间中相邻的编码同样确定只有一位不同,因此末尾都补 1 也一样满足只有一位不同;
- 未翻转区间的第一个编码与翻转区间的最后一个编码相同,因此末尾分别补 0 和 1 后就满足只有一位不同;
- 未翻转区间的最后一个编码与翻转区间的第一个编码相同,因此末尾分别补 0 和 1 后就满足只有一位不同。
综上这样操作后能保证所有编码均符合要求。
【代码】
class Solution {
public:vector<int> grayCode(int n) {vector<int> res = {0, 1}; // n = 1 时编码为 0 和 1for (int i = 1; i < n; i++) {for (int j = res.size() - 1; j >= 0; j--) { // 倒序遍历,这样就是对称的res.push_back(res[j] << 1 | 1); // 左移完将最低位置为 1 后插入数组res[j] <<= 1; // 原本的数直接左移一位,最低位补 0}}return res;}
};
LeetCode 90. 子集 II(中等)
【题目描述】
给你一个整数数组 nums,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。
解集不能包含重复的子集。返回的解集中,子集可以按任意顺序排列。
【示例 1】
输入:nums = [1,2,2]
输出:[[],[1],[1,2],[1,2,2],[2],[2,2]]
【示例 2】
输入:nums = [0]
输出:[[],[0]]
【提示】
1 < = n < = 16 1 <= n <= 16 1<=n<=16
【分析】
本题与 LeetCode 77. & 78. 类似,需要考虑的是本题的数组可能包含重复元素,不能用二进制数来枚举所有选择情况了。
对于重复元素的处理,类似 LeetCode 40.,可以先对数组排序,然后枚举每个数选择的次数即可(方法一)。或者只有与前一个数不同或者相同但前一个数已经被选那么才能选择当前这个数,如果与前一个数相同但是前一个数未被选那么就不能选当前这个数(方法二)。
对于某个位置的数是否已经被选,可以用一个二进制数的第 i i i 位是否为 1 表示 n u m s [ i ] nums[i] nums[i] 是否被选。
【代码】
【方法一】
class Solution {
public:vector<vector<int>> res;vector<int> v;vector<vector<int>> subsetsWithDup(vector<int>& nums) {sort(nums.begin(), nums.end());dfs(nums, 0, 0);return res;}void dfs(vector<int>& nums, int u, int state) { // state 的第 i 位表示 nums[i] 是否已选择if (u == nums.size()) {res.push_back(v);return;}dfs(nums, u + 1, state); // 不选 nums[u]// nums[u] 与 nums[u - 1] 不同或者相同但 nums[u - 1] 已经选过则可以选 nums[u]if (!u || nums[u] != nums[u - 1] || state >> u - 1 & 1) {v.push_back(nums[u]);dfs(nums, u + 1, state | 1 << u);v.pop_back();}}
};
【方法二】
class Solution {
public:vector<vector<int>> res;vector<int> v;vector<vector<int>> subsetsWithDup(vector<int>& nums) {sort(nums.begin(), nums.end());dfs(nums, 0);return res;}void dfs(vector<int>& nums, int u) {if (u == nums.size()) {res.push_back(v);return;}int k = u + 1;while (k < nums.size() && nums[k] == nums[u]) k++; // 共有 k - u 个相同的 nums[u]for (int i = 0; i <= k - u; i++) { // 枚举 nums[u] 的选择数量,注意是先 DFS 再插入dfs(nums, k); // 从下一个不同的数继续搜索v.push_back(nums[u]);}for (int i = 0; i <= k - u; i++) v.pop_back(); // 还原现场}
};

)



