数据分析
NumPy数值计算基础库
官网:NumPy提供了高性能的多维数组对象和工具。
安装
# numpy为数组操作库 ipython 和jupyter类似于 numpy支持的窗口
pip install numpy ipython jupyter
# 启动ipython 查看是否成功ipython --version 退出模式exit
ipython
# jupyter启动 这个是有点类似于前端可视化的方式 运行
jupyter notebook使用
numpy使用
import numpy as np
# [0 1 2 3 4 5 6 7 8 9]
x = np.arange(10)
# 数组平方
y = x ** 2
print(x)
print(y)
# 保存你的数组
np.savez("x_y-squared.npz", x_axis=x, y_axis=y)
# 加载
load_xy = np.load("x_y-squared.npz")
# 打印两列
print(load_xy.files) # ['x_axis', 'y_axis']
# 获取打印
x = load_xy["x_axis"]
y = load_xy["y_axis"]
print(x)
print(y)
ipython使用
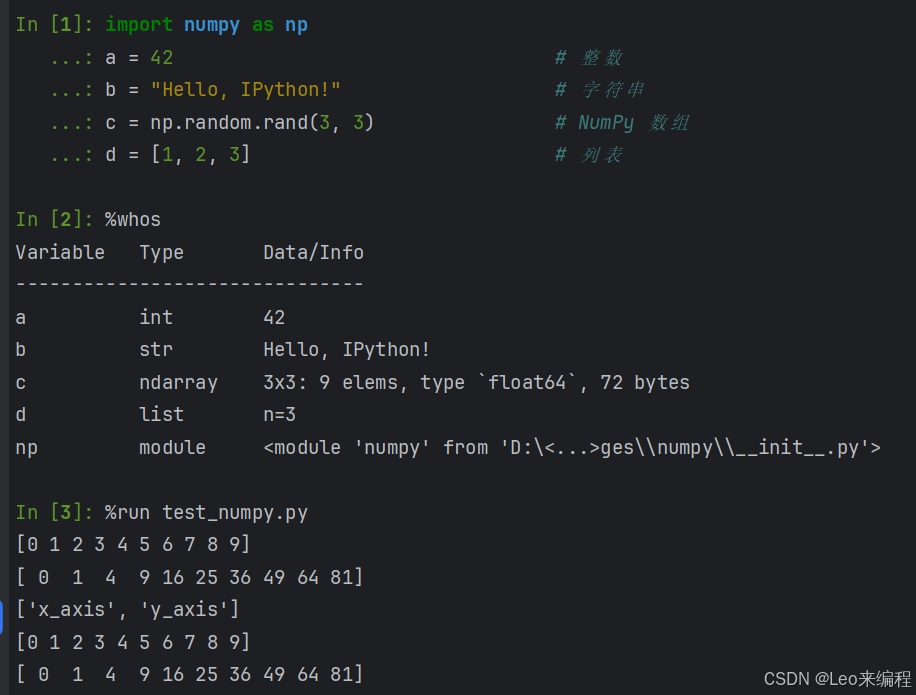
jupyter nodebook 运行后可以使用notebook使用%whos命令跟ipython使用一样的
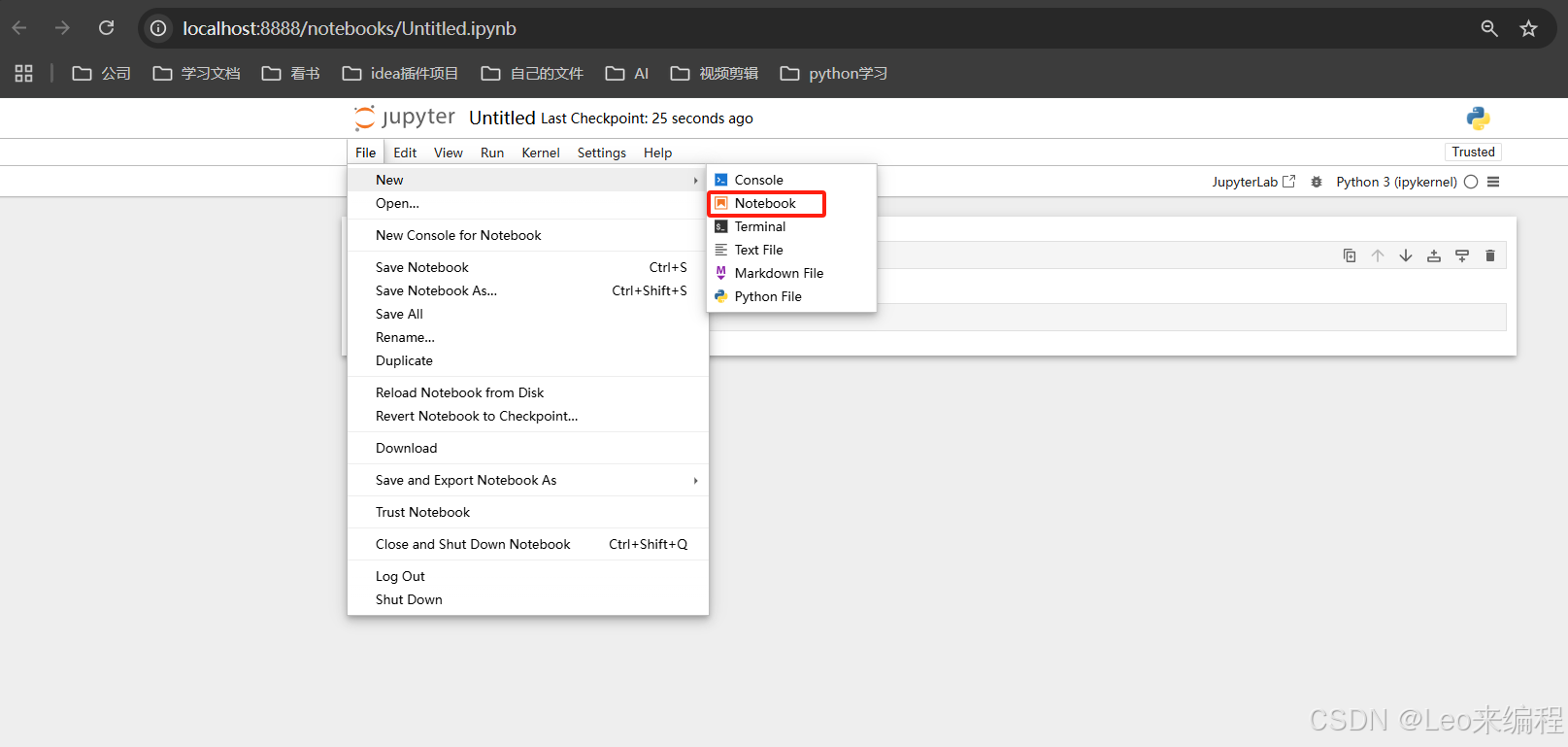
命令行常用命令
命令行可以帮忙分析运行性能,提供更高效的代码编写、调试和探索功能
| 命令 | 功能描述 | 示例 |
|---|---|---|
%whos | 列出变量详细信息(类型/形状/值) | %whos |
%run | 运行外部 Python 脚本 | %run script.py |
%timeit | 测量代码平均执行时间(多次运行) | %timeit sum(range(1000)) |
%matplotlib | 设置 Matplotlib 绘图后端 | %matplotlib inline |
%load | 从文件加载代码到当前单元格 | %load my_function.py |
%debug | 进入事后调试器(分析报错) | %debug |
%cd | 快速切换工作目录 | %cd ~/projects |
%ls | 列出当前目录文件 | %ls -l |
%history | 查看历史命令记录 | %history 1-5 |
%reset | 清除所有变量(慎用) | %reset -f |
%who | 仅列出变量名(简版 %whos) | %who |
%pdb | 自动进入调试模式(异常时) | %pdb on |
%prun | 代码性能分析(CPU 时间) | %prun my_func() |
%%writefile | 将单元格内容保存为文件 | %%writefile output.py |
%autoreload | 自动重载修改的模块 | %autoreload 2 |
numpy常用方法和属性
| 方法/属性 | 类型 | 功能描述 | 示例 |
|---|---|---|---|
np.array() | 方法 | 创建数组 | arr = np.array([1, 2, 3]) |
arr.shape | 属性 | 获取数组形状 | arr.shape → (3,) |
arr.dtype | 属性 | 获取数组数据类型 | arr.dtype → int64 |
np.arange() | 方法 | 生成等差序列数组 | np.arange(0, 10, 2) |
np.linspace() | 方法 | 生成等间隔数组 | np.linspace(0, 1, 5) |
np.zeros() / np.ones() | 方法 | 创建全0或全1数组 | np.zeros((2, 3)) |
arr.reshape() | 方法 | 改变数组形状(不修改数据) | arr.reshape(3, 1) |
np.random.rand() | 方法 | 生成[0,1)均匀分布随机数组 | np.random.rand(2, 2) |
arr.sum() / arr.mean() | 方法 | 求和/均值 | arr.sum(axis=0) |
np.dot() / @ | 方法 | 矩阵乘法 | A @ B |
np.concatenate() | 方法 | 数组拼接 | np.concatenate([a, b]) |
np.save() / np.load() | 方法 | 保存/加载数组到文件 | np.save('data.npy', arr) |
arr.T | 属性 | 数组转置 | arr.T |
np.where() | 方法 | 条件筛选 | np.where(arr > 0) |
np.unique() | 方法 | 返回唯一值 | np.unique(arr) |
Pandas数据分析工具
官网概念:当处理表格数据时,例如存储在电子表格或数据库中的数据,pandas是您的理想工具。pandas将帮助您探索、清理和处理数据。在pandas中,数据表称为DataFrame。
安装
# 核心功能装
pip install pandas
# 选择带参数的
pip install "pandas[excel]"
# 测试
pip install "pandas[test]"
安装参数可选
| 可选参数 | 功能描述 | 包含的依赖库 |
|---|---|---|
pandas[excel] | Excel 文件读写支持 | openpyxl, xlsxwriter, xlrd(仅读取旧版 .xls) |
pandas[parquet] | Parquet 文件格式支持 | pyarrow, fastparquet |
pandas[sql] | SQL 数据库操作支持 | SQLAlchemy |
pandas[html] | HTML 解析支持 | lxml, html5lib, beautifulsoup4 |
pandas[xml] | XML 解析支持 | lxml |
pandas[clipboard] | 剪贴板操作支持 | pyqt5, qtpy 或其他剪贴板后端 |
pandas[performance] | 性能优化(加速计算) | numexpr, bottleneck |
pandas[test] | 测试相关依赖(开发用) | pytest, hypothesis 等 |
pandas[compat] | 兼容性相关依赖 | 如特定版本的 python-dateutil |
pandas[all] | 安装所有可选依赖项(慎用) | 包含上述所有依赖 |
使用
学习文档 :pandas中的基本数据结构,Pandas提供了两种类型的类来处理数据:
-
Series:一个包含任何类型数据的一维标记数组,例如整数、字符串、Python对象等。
-
DataFrame:一种二维数据结构,用于保存数据,如二维数组或具有行和列的表。
以上内容为翻译官网而来,使用ipython进入到命令行模式,如果内容很多使用cls命令清空。
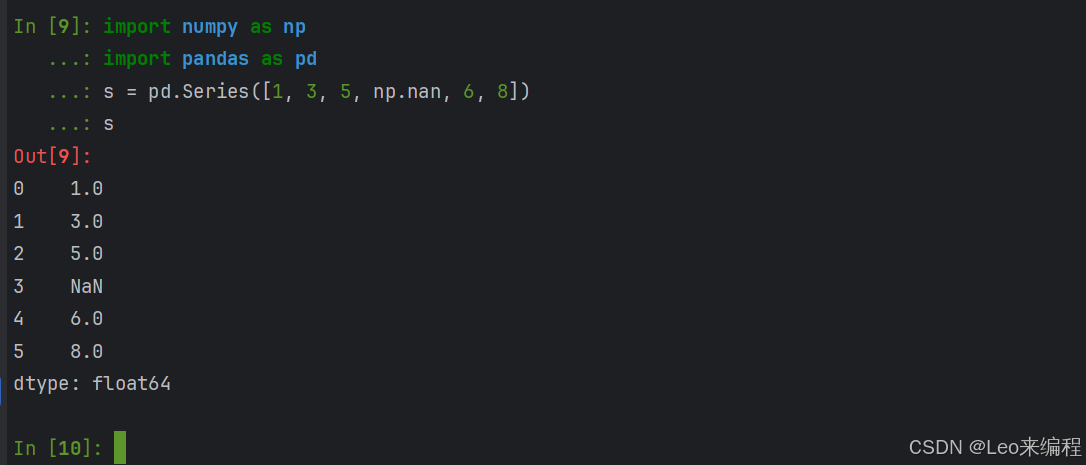
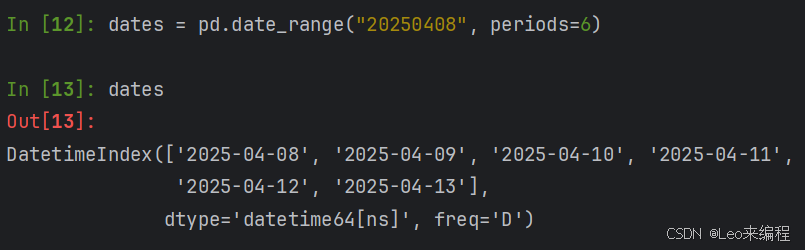
Series常用方法
示例:s = pd.Series([1, 3, 5], index=['a', 'b', 'c'])
| 方法 | 主要参数 | 功能描述 | 示例 |
|---|---|---|---|
values | - | 返回 NumPy 数组 |
结果为:[1 3 5] 类型为:<class 'numpy.ndarray'> |
index | - | 返回索引对象 | s.index 输出 Index(['a', 'b', 'c'], dtype='object') |
head(n) | n=2(默认显示前5行,不填写n走默认) | 返回前n行 |
|
tail(n) | n=2(默认显示后5行,不填写n走默认) | 返回后2行 |
|
isna() / isnull() | - | 检查缺失值(返回布尔Series) | s.isna() |
fillna(value) | value(填充值) | 填充缺失值 | s.fillna(0) |
dropna() | - | 删除缺失值 | s.dropna() |
map(func) | func(函数或字典) | 元素级转换 |
|
apply(func) | func(函数) | 应用函数 |
|
value_counts() | normalize=False(是否标准化) | 统计唯一值频率 |
|
sort_values() | ascending=True(升序) | 按值排序 |
|
unique() | - | 返回唯一值数组 |
|
DataFrame常用方法
示例:df = pd.DataFrame({'A': [1, 2,3], 'B': ['x', 'y','z']})
合并示例:官网中的例子也不错,可以去试试10分钟pandas。
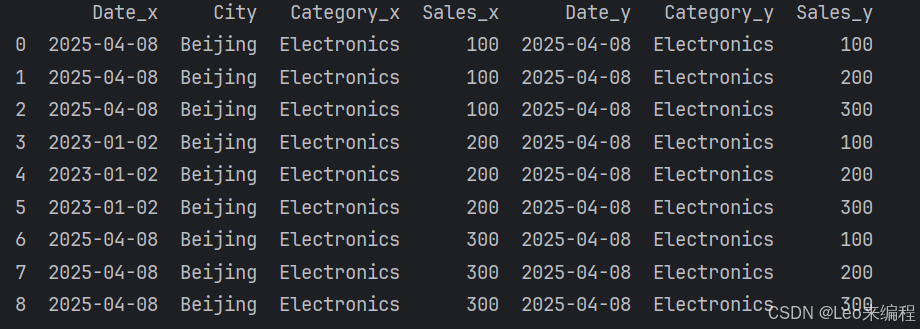
df1 = pd.DataFrame({'Date': ['2025-04-08', '2025-04-08', '2023-01-02']*2,'City': ['Beijing', 'Shanghai']*3,'Category': ['Electronics', 'Clothing']*3,'Sales': [100, 150, 200, 50, 300, 120]
})
df2 = pd.DataFrame({'Date': ['2025-04-08', '2025-04-08', '2025-04-08']*2,'City': ['Beijing', 'chengdu']*3,'Category': ['Electronics', 'Clothing']*3,'Sales': [100, 150, 200, 50, 300, 120]
})
| 方法 | 主要参数 | 功能描述 | 示例 |
|---|---|---|---|
head(n) / tail(n) | n=5 | 返回前/后n行 |
|
shape | - | 返回维度(行数, 列数) |
(3, 2) |
columns | - | 返回列名列表 |
|
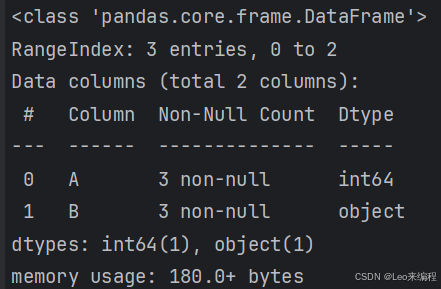
info() | - | 显示数据类型和内存信息 |
|
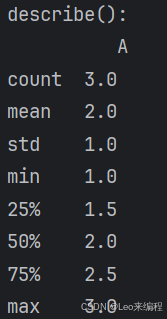
describe() | percentiles=[.25, .75] | 生成统计摘要(数值列) |
|
isna() / isnull() | - | 检查缺失值(返回布尔DataFrame) | df.isna() |
fillna(value) | value(填充值) | 填充缺失值 | df.fillna(0) |
dropna() | axis=0(行/列), how='any'/'all' | 删除缺失值 |
|
drop(columns) | columns(列名列表) | 删除指定列 |
|
groupby() | by(分组键) | 分组聚合 |
|
agg(func) | func(函数或字典) | 多列聚合(如sum, mean) |
|
sort_values() | by(列名), ascending=True | 按值排序 |
|
merge() | right(合并对象), on(键) | 合并DataFrame(类似SQL JOIN) |
|
pivot_table() | values, index, columns | 生成透视表 |
City |
Matplotlib数据可视化
官网:Matplotlib是Python的主要绘图库。
安装
pip install matplotlib使用
import matplotlib.pyplot as plt
import numpy as np# 设置字体为黑体
plt.rcParams['font.family'] = ['SimHei']
x = np.linspace(0, 10, 100)
y = np.sin(x)# 创建画布
plt.figure(figsize=(8, 4))
# 创建折线图
plt.plot(x, y, label='sin(x)', color='blue', linestyle='--', linewidth=2)
# 创建柱状图help(plt.bar)
#plt.bar(x, y, label='sin(x)', color='blue', linestyle='--', linewidth=2)
plt.title("折线图", fontsize=14)
plt.xlabel("X轴", fontsize=12)
plt.ylabel("Y轴", fontsize=12)
plt.grid(True, alpha=0.3)
plt.legend()
# 保存图片 args的路径为项目根路径
plt.savefig('./day30/test_pandas/plot.png', dpi=300)
# plt.savefig('./day30/test_pandas/bar.png', dpi=300)
# 使用show会清空缓存区 所以会导致是白的图片 必须将savefig放到上面
plt.show()
常用图表类型速查表
| 图表类型 | 方法 | 主要参数 | 适用场景 |
|---|---|---|---|
| 折线图 | plt.plot() | x, y, color, linestyle, linewidth, marker, label | 趋势分析、时间序列 |
| 散点图 | plt.scatter() | x, y, s(大小), c(颜色), alpha, cmap | 相关性、分布关系 |
| 柱状图 | plt.bar() | x, height, width, color, edgecolor, label | 分类数据对比 |
| 水平柱状图 | plt.barh() | y, width, 其他同bar() | 长类别名称或排名对比 |
| 直方图 | plt.hist() | x, bins, range, density, alpha, edgecolor | 数据分布统计 |
| 饼图 | plt.pie() | x, labels, autopct, explode, shadow | 占比分析(类别≤6个) |
| 箱线图 | plt.boxplot() | x, notch, vert, patch_artist | 数据离散度、异常值检测 |
| 面积图 | plt.fill_between() | x, y1, y2, alpha, color | 累积趋势或范围强调 |
| 热力图 | plt.imshow() | X, cmap, interpolation, vmin/vmax | 矩阵数据、相关性矩阵 |
| 3D曲面图 | Axes3D.plot_surface() | X, Y, Z, cmap, rstride, cstride | 三维数据可视化 |
核心方法分类表
1. 图形控制
| 方法 | 作用 | 示例 |
|---|---|---|
plt.figure() | 创建画布 | fig = plt.figure(figsize=(8,6)) |
plt.subplot() | 创建子图 | plt.subplot(2,2,1) |
plt.subplots() | 批量创建子图(返回axes数组) | fig, axes = plt.subplots(2,2) |
plt.close() | 关闭图形 | plt.close('all') |
2. 元素定制
| 方法 | 作用 | 示例 |
|---|---|---|
plt.title() | 添加标题 | plt.title("Sales", fontsize=14) |
plt.xlabel() | X轴标签 | plt.xlabel("Time") |
plt.ylabel() | Y轴标签 | plt.ylabel("Price", rotation=0) |
plt.legend() | 显示图例 | plt.legend(loc='upper right') |
plt.grid() | 显示网格 | plt.grid(True, linestyle=':') |
plt.text() | 添加文本 | plt.text(2,5, "Peak") |
3. 坐标轴控制
| 方法 | 作用 | 示例 |
|---|---|---|
plt.xlim() | 设置X轴范围 | plt.xlim(0, 100) |
plt.ylim() | 设置Y轴范围 | plt.ylim(bottom=0) |
plt.xticks() | 设置X轴刻度 | plt.xticks([0,1,2], ['A','B','C']) |
plt.twinx() | 双Y轴(创建第二个Y轴) | ax2 = ax1.twinx() |
4. 样式设置
| 方法/参数 | 作用 | 示例 |
|---|---|---|
plt.style.use() | 使用预设样式 | plt.style.use('ggplot') |
color | 颜色设置(支持名称/十六进制) | color='#FF5733' |
linestyle | 线型('-', '--', ':', '-.') | linestyle='--' |
marker | 标记点('o', 's', '^', 'D'等) | marker='o' |
5. 输出保存
| 方法 | 作用 | 示例 |
|---|---|---|
plt.show() | 显示图形 | plt.show() |
plt.savefig() | 保存图形 | plt.savefig('plot.png', dpi=300) |
代码为day30处,maplotilib试一个就行了,其他的基本跟模版差不多不知道参数啥含义的可以直接查询官网或者使用查询函数的参数翻译可以得知。接下来的是第三段阶段scrapy框架和数据分析的练习,框架会解析某个网站将网站的验证码下载到本地本实现登录这两天会写个需求。





