系列博客目录
文章目录
- 系列博客目录
- 1.distinct关键字 去除重复
- 2.char_length()
- 3.group by 与 count()连用
- 4.date类型有个函数datediff()
- 5.mod 函数
- 6.join和left join的区别
- 1. **`JOIN`(内连接,`INNER JOIN`)**
- 示例:
- 2. **`LEFT JOIN`(左外连接)**
- 示例:
- 总结:
- 用途:
- 7.AVG函数
- 1. **`AVG()` 函数的基本用法**
- 语法:
- 2. **搭配 `GROUP BY` 使用**
- 示例 1:计算每个部门的平均薪资
- 示例 2:计算每个学生的平均成绩
- 3. **不搭配 `GROUP BY` 使用**
- 示例:计算所有员工的平均薪资
- 4. **处理 `NULL` 值**
- 5. **总结**
- 8.
- 9.CONCAT UPPER LOWER SUBSTRING
- 10.
1.distinct关键字 去除重复
select distinct author_id as id from Views where author_id = viewer_id order by id;
2.char_length()
select tweet_id from Tweets where char_length(content) > 15;
3.group by 与 count()连用
select customer_id, count(customer_id) as count_no_trans
from Visits left join Transactions on Visits.visit_id = Transactions.visit_id
where transaction_id is null group by customer_id;
4.date类型有个函数datediff()
select a.id
from Weather as a cross join Weather as b on datediff(a.recordDate, b.recordDate) = 1
where a.temperature > b.temperature;
5.mod 函数
select * from cinema where mod(id, 2) = 1 and description != 'boring' order by rating desc;
6.join和left join的区别
在 MySQL 中,JOIN 和 LEFT JOIN 都用于将两个或多个表连接在一起,但它们之间有重要的区别:
1. JOIN(内连接,INNER JOIN)
- 定义:
JOIN默认是INNER JOIN,表示仅返回两个表中满足连接条件的行。如果一个表中的某一行在另一个表中没有对应的匹配行,那么该行就不会出现在查询结果中。 - 行为:
INNER JOIN返回的是两个表中匹配的数据行,若某个表的某行在另一个表中找不到对应的匹配行,那么这一行就不会出现在查询结果中。
示例:
假设有两个表:
-
students(学生表)id name 1 Alice 2 Bob 3 Charlie -
courses(课程表)student_id course 1 Math 2 Science 4 History
查询:SELECT students.name, courses.course FROM students JOIN courses ON students.id = courses.student_id;
结果:
| name | course |
|---|---|
| Alice | Math |
| Bob | Science |
- 只有
students和courses表中匹配的行会出现在结果中,Charlie没有参加任何课程,所以不会出现在结果中。
2. LEFT JOIN(左外连接)
- 定义:
LEFT JOIN返回左表(即FROM后指定的第一个表)中的所有行,即使这些行在右表(即JOIN后指定的表)中没有匹配项。如果左表中的某行在右表中找不到对应的匹配行,那么右表中的字段会用NULL填充。 - 行为:
LEFT JOIN返回的是左表中的所有数据行,若右表没有与左表行匹配的数据,则右表的列将会用NULL填充。
示例:
使用同样的表 students 和 courses,查询:SELECT students.name, courses.course FROM students LEFT JOIN courses ON students.id = courses.student_id;
结果:
| name | course |
|---|---|
| Alice | Math |
| Bob | Science |
| Charlie | NULL |
- 即使
Charlie没有参加任何课程,LEFT JOIN仍然返回了Charlie的数据行,并且courses.course列显示为NULL。
总结:
JOIN(INNER JOIN):只返回两个表中匹配的行。如果某行在另一个表中没有对应的行,则该行不会出现在结果中。LEFT JOIN(左外连接):返回左表(FROM后的表)中的所有行,即使右表中没有匹配的行。如果右表没有匹配项,右表的字段会填充NULL。
用途:
INNER JOIN:用于只关心两个表中匹配的记录,常见于查询需要联动的数据。LEFT JOIN:用于查询左表中的所有数据,即使右表没有匹配的记录。例如,查询所有学生及其参加的课程,即使有些学生没有参加任何课程。
mysql中join 我后面不加条件呢?在 MySQL 中,如果在使用 JOIN 时不加连接条件,会发生笛卡尔积(Cartesian Product)。笛卡尔积是指将两个表的每一行与另一个表的每一行进行配对,导致结果集的行数是两个表行数的乘积。
7.AVG函数
AVG() 函数是 SQL 中一个聚合函数,用于计算某一列的 平均值。它会计算某列所有非 NULL 值的平均数。
1. AVG() 函数的基本用法
AVG() 函数可以用于数值型数据列(如整数、浮动数等),它返回该列的平均值。
语法:
AVG(column_name)
column_name:要计算平均值的列。
2. 搭配 GROUP BY 使用
通常,AVG() 函数会与 GROUP BY 子句一起使用,这样可以对数据进行分组计算每个组的平均值。GROUP BY 会根据指定的列对数据进行分组,AVG() 会分别计算每个分组的平均值。
示例 1:计算每个部门的平均薪资
假设有一个员工表 employees,包含以下字段:employee_id、department、salary。
SELECT department, AVG(salary) AS avg_salary
FROM employees
GROUP BY department;
解释:
AVG(salary):计算每个部门的平均薪资。GROUP BY department:将数据按部门进行分组,对每个部门计算薪资的平均值。
结果:
| department | avg_salary |
|---|---|
| HR | 5000 |
| IT | 6000 |
| Sales | 4500 |
这个查询的结果是每个部门的平均薪资。
示例 2:计算每个学生的平均成绩
假设有一个 students 表,记录学生的成绩:
SELECT student_id, AVG(score) AS avg_score
FROM scores
GROUP BY student_id;
解释:
AVG(score):计算每个学生的平均成绩。GROUP BY student_id:按学生的 ID 对数据进行分组。
结果:
| student_id | avg_score |
|---|---|
| 1 | 85.5 |
| 2 | 78.0 |
3. 不搭配 GROUP BY 使用
如果不使用 GROUP BY,AVG() 会计算整个数据集的平均值,而不是每个分组的平均值。
示例:计算所有员工的平均薪资
如果你不使用 GROUP BY,就会得到整个表的平均值。
SELECT AVG(salary) AS avg_salary
FROM employees;
结果:
| avg_salary |
|---|
| 5500 |
这个查询计算的是所有员工的平均薪资,而没有分组。
4. 处理 NULL 值
AVG() 会忽略 NULL 值,它只会计算那些非 NULL 的记录。例如,如果某个员工的薪资为 NULL,则该值不会影响平均薪资的计算。
5. 总结
AVG()函数计算某列的平均值。GROUP BY通常与AVG()配合使用,用于对数据进行分组并计算每个分组的平均值。- 如果不使用
GROUP BY,AVG()会计算整个表的平均值。 AVG()会忽略NULL值。
AVG() 是常用的聚合函数之一,用于执行汇总统计,特别适用于报告和数据分析任务。
8.
select Product.product_id, product_name
from Product left join Sales on Product.product_id = Sales.product_id
group by product_id
having count(sale_date between '2019-01-01' and '2019-03-31' or null) = count(*);
这里值得注意的是count的条件用法。举个例子count(age > 20 or null)这个语句,里面or null必须加,否则就等价于count(*)了,要么就是写作sum(age > 20)也可以。
我猜测是因为age > 20返回的是0或者1,而count对于不管是0还是1,都是会计数一次的,只有Null不会被计数。所以这个age > 20 or null表达的是不大于20就转换为null,这样就不会被count计数
作者:喜刷刷
链接:https://leetcode.cn/problems/sales-analysis-iii/description/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
9.CONCAT UPPER LOWER SUBSTRING
SELECT user_id, CONCAT(UPPER(SUBSTRING(name, 1, 1)), LOWER(SUBSTRING(name, 2))) AS name
FROM Users
ORDER BY user_id;
SUBSTRING(string, start, length)
string:要从中提取子字符串的原始字符串。
start:子字符串的起始位置(从 1 开始)。
length:要提取的字符数(可选,如果省略,则提取从起始位置到字符串末尾的所有字符)。
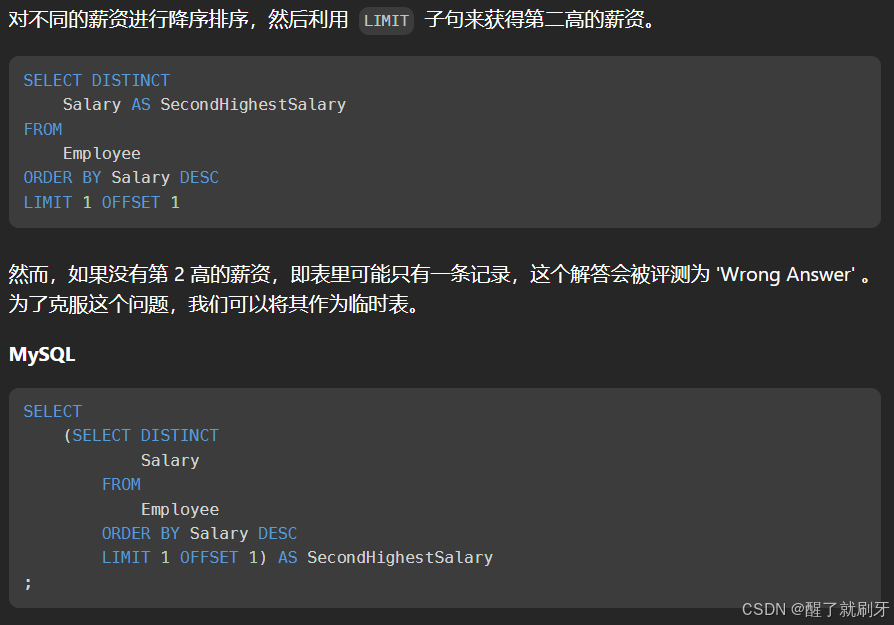
10.
select
(select distinct salary
from Employee
order by salary desc
limit 1 offset 1 ) as SecondHighestSalary ;虽然这没有显式创建临时表,但在某种意义上,子查询的结果就充当了临时表的角色。




:cat)
——select)