强化学习算法
(一)动态规划方法——策略迭代算法(PI)和值迭代算法(VI)
(二)Model-Free类方法——蒙特卡洛算法(MC)和时序差分算法(TD)
(三)基于动作值的算法——Sarsa算法与Q-Learning算法
(四)深度强化学习时代的到来——DQN算法
(五)最主流的算法框架——AC算法(AC、A2C、A3C、SAC)
(六)应用最广泛的算法——PPO算法与TRPO算法
(七)更高级的算法——DDPG算法与TD3算法
(八)待续
文章目录
- 强化学习算法
- 前言
- 一、核心思想
- 二、 DQN算法的核心技术
- 1. 经验回放
- 2. 目标网络
- 三、代码实验
- 四、总结
前言
前面学习的Sarsa和Q-Learning均是针对离散有限状态问题,对于状态空间连续的问题若仍采用此类方法将会有极大的计算花销,因此这章开始将介绍用于求解状态空间连续的算法——DQN,该算法被广泛应用于各领域同时也被认为是早期与深度学习算法结合最成功的算法。
一、核心思想
DQN算法也可以称为Deep Q-Learning算法,从名字可以看出该算法与Q-Learning算法有很大的联系。Q-Learning算法的核心是通过动作价值公式更新最优策略的状态-动作价值表(Q-Table),而当状态空间连续时,Q-Table表将会变的无限大;DQN算法的目的就是通过神经网络的方法拟合这一表格。我们可以对比一下两种算法的核心公式:
- Q-Learning算法核心更新公式
Q ( s t , a t ) ← Q ( s t , a t ) + α [ R t + 1 + γ max a Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] Q(s_t,a_t)←Q(s_t,a_t)+α[R_{t+1}+γ\max_{a}Q(s_{t+1},a_{t+1})-Q(s_t,a_t)] Q(st,at)←Q(st,at)+α[Rt+1+γamaxQ(st+1,at+1)−Q(st,at)] - DQN算法的损失函数
L ( θ ) = E [ ( R t + 1 + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ − ) − Q ( s t , a t ; θ ) ) 2 ] \mathcal{L} (\theta)=\mathbb{E}[(R_{t+1}+γ\max_{a_{t+1}}Q(s_{t+1},a_{t+1};\theta^-)-Q(s_t,a_t;\theta))^2] L(θ)=E[(Rt+1+γat+1maxQ(st+1,at+1;θ−)−Q(st,at;θ))2]公式中,Q每次更新时选取下一状态的最大Q值,这一做法直接源于贝尔曼最优方程的设计。不同之处在于Q-Learning算法每次会直接优化Q-Table中对应的Q值,而DQN算法的优化对象是拟合函数的参数。
二、 DQN算法的核心技术
DQN算法的实现主要依赖其两大核心技术,分别是经验回放、目标网络。这两种技术在未来的很多算法中都有应用,很多算法都会将这两种技术做为算法的小技巧提升算法性能,下面我们分别介绍这两种技术
1. 经验回放
连续采样的经验之间存在强时间相关性。在CartPole环境中,连续的多次状态转移可能都是向左倾斜时的杆角度微小变化,这样将会使网络参数的梯度更新方向总是偏向局部特征,进而导致训练不稳定,收敛困难。且在线学习中,每个经验使用一次后即丢弃,造成了数据的浪费。策略初始时随机探索,后期逐渐趋近最优策略,导致早期经验被覆盖丢失。
DQN采用经验回放技术解决上述问题,其核心思想是将Agent与环境交互产生的经验(即状态转移样本)存储在一个固定容量的缓冲区中,训练时从中随机采样批次数据进行网络更新。缓冲池中的数据通常一队列的形式存储经验,并以随机均匀采样的方式采样,打破样本的时间相关性,提高数据利用率。
2. 目标网络
DQN网络采用神经网络的方式拟合状态动作价值表,它通过当前网络和目标网络两个网络合作完成工,其中目标网络是DQN算法的核心设计之一,其本质是通过固定部分参数来稳定训练目标,解决自举(Bootstrapping)带来的偏差和训练震荡问题。
这里解释一下问什么需要目标网络,而不是直接用单个网络拟合Q表。我们可以假设,若使用在线的单个网络自身计算TD目标值,每次参数更新后,Q值的估计目标会不断变化,导致训练目标"追逐移动靶"。智能体在状态 s s s选择动作 a a a后到达 s t + 1 s_{t+1} st+1,此时若采用单个在线网络计算最大的下一动作Q值,则在线网络参数 θ \theta θ在训练中频繁变化,同一状态下的Q值在不同时间下变化极大,难以收敛;若采样两个网络,并将目标网络相对于当前网络滞后更新,就能使误差不会立即传播到目标计算中,相当于在时间轴上平滑了误差。
我们可以将目标网络与当前网络简单类比一下:
在线网络:像一个正在学习的学生,不断尝试和调整自己的知识。
目标网络:像一本权威教科书,知识更新较慢但稳定,学生参考书中的知识(目标值)来修正自己的理解。
三、代码实验
由于DQN算法主要针对连续性状态空间问题,我们之前的网格迷宫问题属于离散状态空间问题,并不适用与DQN算法,因此从本章开始在Gym中的Cart-Pole环境对算法进行测试,具体实现代码如下:
import gym
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei', # 中易黑体 (Windows)'Microsoft YaHei', # 微软雅黑 (Windows)'WenQuanYi Zen Hei', # 文泉驿正黑 (Linux)'Arial Unicode MS' # macOS
]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 超参数设置
BATCH_SIZE = 64 # 经验回放采样批量大小
GAMMA = 0.99 # 折扣因子
EPSILON_START = 1.0 # 初始探索率
EPSILON_END = 0.01 # 最小探索率
EPSILON_DECAY = 0.995 # 探索率衰减率
TARGET_UPDATE = 10 # 目标网络更新频率(步数)
LR = 0.001 # 学习率
MEMORY_CAPACITY = 10000 # 经验回放缓冲区容量
reward_list = []# 定义设备(自动检测GPU可用性)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 定义Q网络结构(全连接神经网络)
class DQN(nn.Module):def __init__(self, state_dim, action_dim):super(DQN, self).__init__()self.fc = nn.Sequential(nn.Linear(state_dim, 128),nn.ReLU(),nn.Linear(128, 128),nn.ReLU(),nn.Linear(128, action_dim))def forward(self, x):return self.fc(x)# 经验回放缓冲区
class ReplayBuffer:def __init__(self, capacity):self.buffer = deque(maxlen=capacity) # 使用deque实现自动覆盖旧数据def push(self, state, action, reward, next_state, done):self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size):return random.sample(self.buffer, batch_size)def __len__(self):return len(self.buffer)# DQN智能体
class DQNAgent:def __init__(self, state_dim, action_dim):self.action_dim = action_dimself.epsilon = EPSILON_START# 创建当前网络和目标网络self.policy_net = DQN(state_dim, action_dim).to(device)self.target_net = DQN(state_dim, action_dim).to(device)# TODO:在 PyTorch 等深度学习框架中,即使两个网络结构完全相同,它们的初始参数默认也是不同的self.target_net.load_state_dict(self.policy_net.state_dict()) # 初始化目标网络self.optimizer = optim.Adam(self.policy_net.parameters(), lr=LR)self.memory = ReplayBuffer(MEMORY_CAPACITY)self.loss_fn = nn.MSELoss()def choose_action(self, state):""" ε-greedy策略选择动作 """if random.random() < self.epsilon:return random.randint(0, self.action_dim - 1) # 随机探索else:with torch.no_grad():state_tensor = torch.FloatTensor(state).to(device)q_values = self.policy_net(state_tensor)return q_values.argmax().item() # 选择Q值最大的动作def update_epsilon(self):""" 衰减探索率 """self.epsilon = max(EPSILON_END, self.epsilon * EPSILON_DECAY)def update_model(self):""" 从经验回放中采样并更新网络参数 """if len(self.memory) < BATCH_SIZE:return# 1. 从缓冲区采样一批经验batch = self.memory.sample(BATCH_SIZE)states, actions, rewards, next_states, dones = zip(*batch)# 转换为PyTorch张量states = torch.FloatTensor(np.array(states)).to(device)actions = torch.LongTensor(actions).to(device)rewards = torch.FloatTensor(rewards).to(device)next_states = torch.FloatTensor(np.array(next_states)).to(device)dones = torch.BoolTensor(dones).to(device)# 2. 计算当前Q值 (Q_actual)current_q = self.policy_net(states).gather(1, actions.unsqueeze(1))# 3. 计算目标Q值 (Q_target)with torch.no_grad():next_q = self.target_net(next_states).max(1)[0] # 目标网络计算maxQ(s',a')target_q = rewards + (1 - dones.float()) * GAMMA * next_q# 4. 计算均方误差损失loss = self.loss_fn(current_q.squeeze(), target_q)# 5. 反向传播优化self.optimizer.zero_grad()loss.backward()self.optimizer.step()def update_target_net(self):""" 更新目标网络参数(硬更新) """self.target_net.load_state_dict(self.policy_net.state_dict())# 训练流程
def train_dqn(env_name, episodes):env = gym.make(env_name)state_dim = env.observation_space.shape[0]action_dim = env.action_space.nagent = DQNAgent(state_dim, action_dim)total_steps = 0for episode in range(episodes):state = env.reset()[0]episode_reward = 0done = Falsewhile not done:# 1. 选择并执行动作action = agent.choose_action(state)next_state, reward, terminated, truncated, _ = env.step(action)done = terminated or truncated # 合并终止条件# 2. 存储经验到缓冲区agent.memory.push(state, action, reward, next_state, done)# 3. 更新当前网络agent.update_model()state = next_stateepisode_reward += rewardtotal_steps += 1# 4. 定期更新目标网络if total_steps % TARGET_UPDATE == 0:agent.update_target_net()# 衰减探索率agent.update_epsilon()# 打印训练进度if (episode + 1) % 10 == 0:print(f"Episode: {episode + 1}, Reward: {episode_reward}, Epsilon: {agent.epsilon:.3f}")reward_list.append(episode_reward)env.close()if __name__ == "__main__":env_name = "CartPole-v1"episodes = 2000train_dqn(env_name, episodes)np.save(f"result/dqn_rewards.npy", np.array(reward_list))plt.plot(range(episodes), reward_list)plt.xlabel('迭代次数')plt.ylabel('每代的总奖励值')plt.title('DQN的训练过程')plt.grid(True)plt.show()上面的代码将每次迭代的奖励值存储在了“result/dqn_rewards.npy”中,后面的算法我们都会存储在这个文件夹下,便于算法性能的对比,对比的绘图函数代码如下所示:
import numpy as np
import matplotlib.pyplot as plt# 加载数据(注意路径与图中一致)
dqn_rewards = np.load("dqn_rewards.npy")
plt.figure(figsize=(12, 6))# 绘制原始曲线
plt.plot(dqn_rewards, alpha=0.3, color='blue', label='DQN (原始)')# 绘制滚动平均曲线(窗口大小=50)
window_size = 50
plt.plot(np.convolve(dqn_rewards, np.ones(window_size)/window_size, mode='valid'),linewidth=2, color='navy', label='DQN (50轮平均)')# 图表标注
plt.xlabel('训练轮次 (Episodes)', fontsize=12, fontfamily='SimHei')
plt.ylabel('奖励值', fontsize=12, fontfamily='SimHei')
plt.title('DQN 训练对比 (CartPole-v1)', fontsize=14, fontfamily='SimHei')
plt.legend(loc='upper left', prop={'family': 'SimHei'})
plt.grid(True, alpha=0.3)# 保存图片(解决原图未保存的问题)
# plt.savefig('comparison.png', dpi=300, bbox_inches='tight')
plt.show()
结果图如下:
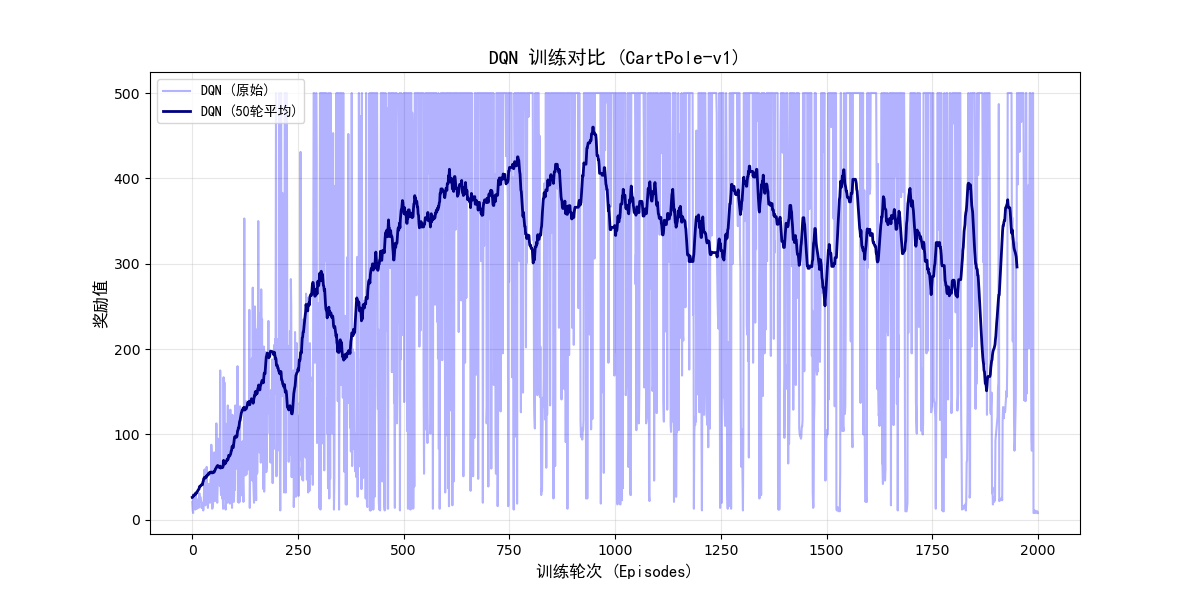
四、总结
对比一下Q-Learning和DQN
| 特性 | Q-Learning | DQN |
|---|---|---|
| Q值表示 | 离散的Q表 | 神经网络近似 |
| 核心公式 | Q ( s t , a t ) ← Q ( s t , a t ) + α [ R t + 1 + γ max a Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] Q(s_t,a_t)←Q(s_t,a_t)+α[R_{t+1}+γ\max_{a}Q(s_{t+1},a_{t+1})-Q(s_t,a_t)] Q(st,at)←Q(st,at)+α[Rt+1+γmaxaQ(st+1,at+1)−Q(st,at)] | L ( θ ) = E [ ( R t + 1 + γ max a t + 1 Q ( s t + 1 , a t + 1 ; θ − ) − Q ( s t , a t ; θ ) ) 2 ] \mathcal{L} (\theta)=\mathbb{E}[(R_{t+1}+γ\max_{a_{t+1}}Q(s_{t+1},a_{t+1};\theta^-)-Q(s_t,a_t;\theta))^2] L(θ)=E[(Rt+1+γmaxat+1Q(st+1,at+1;θ−)−Q(st,at;θ))2] |
| 状态空间 | 低位离散 | 高维连续 |
| 动作空间 | 离散(有限动作集合) | 离散(有限动作集合) |
| 泛化能力 | 无法处理未见过的状态 | 神经网络可泛化到相似状态 |
| 数据使用 | 在线学习单步更新 | 离散学习批量更新 |
环境下,需要手动实现队列机制来替代FreeRTOS的CAN发送接收函数)


