目录
- 6.4 生成增强
- 6.4.1 何时增强
- 1)外部观测法
- 2)内部观测法
- 6.4.2 何处增强
- 6.4.3 多次增强
- 6.4.4 降本增效
- 1)去除冗余文本
- 2)复用计算结果
6.4 生成增强
检索器得到相关信息后,将其传递给大语言模型以期增强模型的生成能力。利用这些信息进行生成增强是一个复杂的过程,不同的方式会显著影响 RAG 的性能。
如何优化增强过程围绕四个方面讨论:
-
何时增强,确定何时需要检索增强,以确保非必要不增强;
-
何处增强,确定在模型中的何处融入检索到的外部知识,以最大化检索的效用;
-
多次增强,如何对复杂查询与模糊查询进行多次迭代增强,以提升 RAG 在困难问题上的效果;
-
降本增效,如何进行知识压缩与缓存加速,以降低增强过程的计算成本。
.
6.4.1 何时增强
大语言模型在训练过程中掌握了大量知识,这些知识被称为内部知识(Self Knowledge)。对于内部知识可以解决的问题,我们可以不对该问题进行增强。
不对是否需要增强进行判断而盲目增强,可能引起生成效率和生成质量上的双下降。
判断是否需要增强的核心在于判断大语言模型是否具有内部知识。两种方法:
-
外部观测法,通过 Prompt 直接询问模型是否具备内部知识,或应用统计方法对是否具备内部知识进行估计,这种方法无需感知模型参数;
-
内部观测法,通过检测模型内部神经元的状态信息来判断模型是否存在内部知识, 这种方法需要对模型参数进行侵入式的探测。
1)外部观测法
外部观测法:通过直接对大语言模型进行询问或者观测调查其训练数据来推断其是否具备内部知识。判断方法有:
-
Prompt 直接询问大语言模型是否含有相应的内部知识
-
反复询问大语言模型同一个问题观察模型多次回答的一致性。
-
翻看训练数据来判断其是否具备内部知识。
-
设计伪训练数据统计量来拟合真实训练数据的分布,间接评估模型对知识的学习情况。比如,由于模型对训练数据中低频出现的知识掌握不足,而对更“流行”(高频)的知识掌握更好,因此实体的流行度作可以作为伪训练数据统计量。
2)内部观测法
分析模型在生成时内部每一层的隐藏状态变化,比如注意力模块的输出、多层感知器 (MLP) 层的输出与激活值变化等,来进行评估其内部知识水平。
模型的中间层前馈网络在内部知识检索中起关键作用,通过训练线性分类器(探针)可区分问题是否属于模型“已知”或“未知”。研究针对注意力层输出、MLP层输出和隐层状态三种内部表示设计实验,结果表明大语言模型利用中间层隐藏状态进行分类时准确率较高,验证了中间层能有效反映模型对问题的知识储备。
.
6.4.2 何处增强
在确定大语言模型需要外部知识后,我们需要考虑在何处利用检索到的外部知识,即何处增强的问题。
输入端、中间层和输出端都可以进行知识融合操作:
-
在输入端,可将问题和检索到的外部知识拼接在 Prompt 中;
-
在中间层,可以采用交叉注意力将外部知识直接编码到模型的隐藏状态中;
-
在输出端,可以利用外部知识对生成的文本进行后矫正。
.
6.4.3 多次增强
实际应用中,用户对大语言模型的提问可能是复杂或模糊的。
-
处理复杂问题时,常采用分解式增强的方案。该方案将复杂问题分解为多个子问题,子问题间进行迭代检索增强, 最终得到正确答案。
-
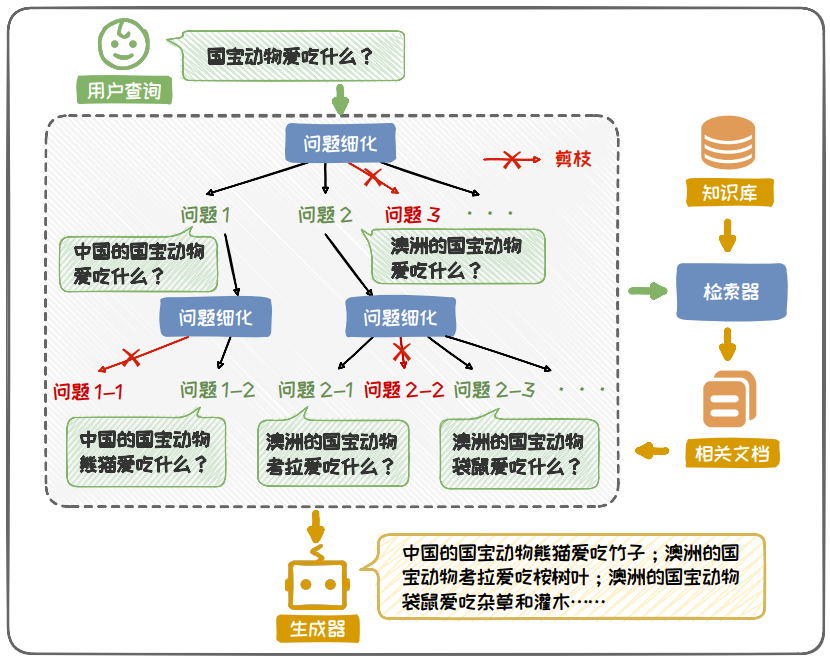
处理模糊问题时,常采用渐进式增强的方案。该方案将问题的不断细化,然后分别对细化的问题进行检索增强,力求给出全面的答案,以覆盖用户需要的答案。
图 6.24: DSP 流程示意图(分解式增强)
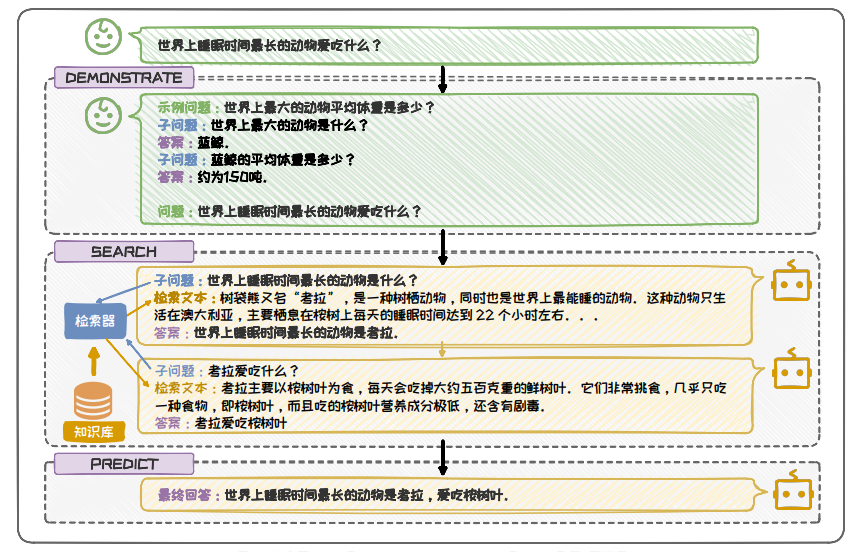
图 6.25: TOC 框架流程示意图(渐进式增强)
.
6.4.4 降本增效
检索出的外部知识通常包含大量原始文本。将其通过 Prompt 输入给大语言模型时,会大幅度增加输入 Token 的数量,从而增加了大语言模型的推理计算成本。
此问题可从去除冗余文本与复用计算结果两个角度进行解决。
1)去除冗余文本
去除冗余文本的方法通过对检索出的原始文本的词句进行过滤,从中选择出部分有益于增强生成的部分。
去除冗余文本的方法主要分为三类:
-
Token级别的方法:
-
子文本级别的方法;
-
全文本级别的方法。
(1)Token级别的压缩方法:
通过评估Token的困惑度来剔除冗余信息。困惑度低的Token表示信息量少,可能是冗余的;困惑度高的Token则包含更多信息。LongLLMLingua框架利用小模型计算困惑度,首先进行粗粒度压缩,通过文档的困惑度均值评估其重要性;然后进行细粒度压缩,逐个Token评估并删除低困惑度的Token。此外,该方法还引入了文档重排序、动态压缩比率和子序列恢复机制,以确保重要信息被有效保留。
(2)子文本级别方法通过:
评估子文本的有用性进行成片删除。FITRAG方法利用双标签子文档打分器,从事实性和模型偏好两个维度评估子文档。具体步骤为:滑动窗口分割文档,双标签打分器评分,最后删除低评分子文档以去除冗余。
(3)全文本级别方法:
通过训练信息提取器直接从文档中抽取出重要信息以去除冗余。PRCA方法分为两个阶段:
-
上下文提取阶段:通过监督学习最小化压缩文本与原始文档的差异,训练提取器将文档精炼为信息丰富的压缩文本。
-
奖励驱动阶段:利用大语言模型作为奖励模型,根据压缩文本生成答案与真实答案的相似度作为奖励信号,通过强化学习优化提取器。
最终,经典方法PRCA能够端到端地将输入文档转化为压缩文本,高效去除冗余信息。
2)复用计算结果
可以对计算必需的中间结果进行复用,以优化 RAG 效率。
(1)KV-cache 复用
在大语言模型推理自回归过程中,每个 Token 都要用之前 Token 注意力模块的 Key 和 Value 的结果。为避免重新计算,我们将之前计算的 Key 和 Value 的结果进行缓存(即 KV-cache),在需要是直接从 KV-cache 中调用。
然而,随着输入文本长度的增加,KV-cache 的 GPU 显存占用会显著增加,甚至超过模型参数的显存占用。
图 6.26: RAGCache 框架流程示意图
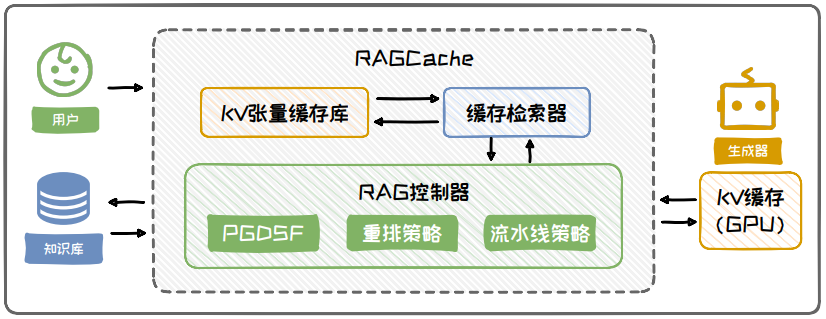
不过,RAG 中不同用户查询经常检索到相同的文本,而且常见的查询通常数量有限。因此,我们可以将常用的重复文本的 KV-cache 进行复用。基于此,RAGCache 设计了一种 RAG 系统专用的多级动态缓存机制,核心部分:
-
KV 张量缓存库:采用树结构来缓存所计算出的文档 KV 张量,其中每个树节点代表一个文档;
-
缓存检索器:负责在缓存库中快速查找是否存在所需的缓存节点;
-
RAG 控制器:作为系统的策略中枢,负责制定核心的缓存策略。
为优化 RAG 性能,RAG 控制器采用了以下策略:
-
PGDSF 替换策略:通过综合考虑文档的访问频率、大小、访问成本和最近访问时间,优化频繁使用文档的检索效率。
-
重排策略:调整请求处理顺序,优先处理高缓存利用率的请求,减少重新计算的需求。
-
动态推测流水线策略:并行执行 KV 张量检索和模型推理,降低端到端延迟。
.
其他参考:【大模型基础_毛玉仁】系列文章
声明:资源可能存在第三方来源,若有侵权请联系删除!






