1.在WordCountDriver里面将链接集群注释了

2.然后创建CustomPartitioner类
package com.example.mapreduce;
//自定义分区器
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
//1.继承Partitioner类
//2.重写getPartition方法
public class CustomPartitioner extends Partitioner<Text, LongWritable> {
@Override
public int getPartition(Text key, LongWritable value, int numPartitions) {
//返回值是0,1,2.....
//如果Key1和Key2的code相同,那么他们会被分配到同一个分区,保存到同一个文件
//如果单词是以a~m开头,那么会被分配到第一个分区
//否则,就分配到第二个分区
//1.获取单词首字符
char firstChar = key.toString().charAt(0);
//2.判断首字符
if (firstChar >= 'a' && firstChar <= 'm') {
return 0;
}else {
return 1;
}
}
}
3.然后回到我们 WordCountDriver
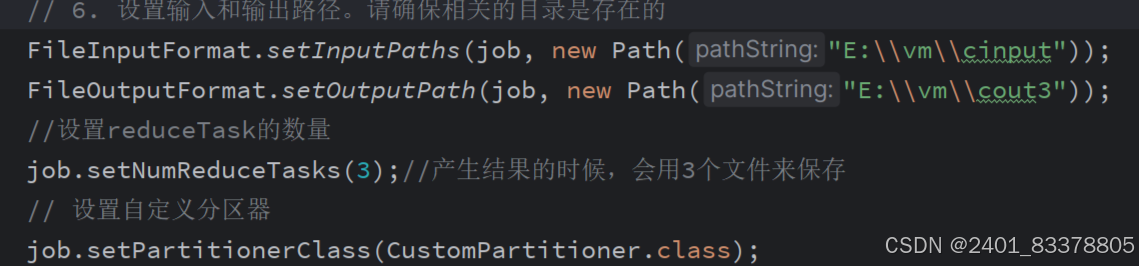
在“// 6. 设置输入和输出路径。请确保相关的目录是存在的”后面添加
//设置reduceTask的数量
job.setNumReduceTasks(3);//产生结果的时候,会用3个文件来保存
// 设置自定义分区器
job.setPartitionerClass(CustomPartitioner.class);





:两数之和,三数之和,四数之和)