为了建模多标签之间的依赖关系,本篇工作用序列生成的方式来解决该问题。
当前label的预测不仅依赖于输入上下文,也依赖于已输出的所有label。用seq2seq建模标签依赖是一种非常自然的思路,但存在如下两大问题:
- 序列建模强调标签的先后顺序,即位置关系,而多标签是一个集合,不存在位置约束,哪个标签在前在后没有关系,只要输出正确就行。这种情况下,ground truth该如何构造?
- 序列生成是自回归形式,当前label的生成依赖于上一个label,如果上一个label是错误的,那么将会严重影响后续所有label的预测。这种情况下,该减轻预测错误的label所导致的连锁反应?
SGM针对上述问题提出了如下建模思路:
模型结构
经典的序列生成范式:
p ( y ∣ x ) = ∏ i = 1 n p ( y i ∣ y 1 , y 2 , ⋯ , y i − 1 , x ) p(\boldsymbol{y} \mid \boldsymbol{x})=\prod_{i=1}^n p\left(y_i \mid y_1, y_2, \cdots, y_{i-1}, \boldsymbol{x}\right) p(y∣x)=i=1∏np(yi∣y1,y2,⋯,yi−1,x)
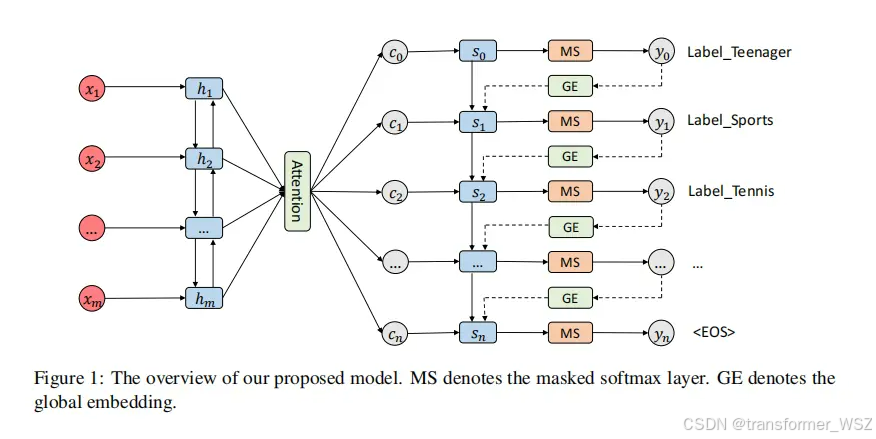
问题1的解法
作者根据训练集中标签出现的频次来构造标签序列:高频标签置前,低频标签置后。同时在序列头尾插入 bos 和 eos 表示序列的开始与结束。
问题2的解法
引入Global Embedding考虑所有可能label的信息,避免贪心依赖上一个label:
e ‾ = ∑ i = 1 L y t − 1 ( i ) e i g ( y t − 1 ) = ( 1 − H ) ⊙ e + H ⊙ e ‾ H = W 1 e + W 2 e ‾ \overline{\boldsymbol{e}}=\sum_{i=1}^L y_{t-1}^{(i)} \boldsymbol{e}_i \\ g\left(\boldsymbol{y}_{t-1}\right)=(\mathbf{1}-\boldsymbol{H}) \odot \boldsymbol{e}+\boldsymbol{H} \odot \overline{\boldsymbol{e}} \\ \boldsymbol{H}=\boldsymbol{W}_1 \boldsymbol{e}+\boldsymbol{W}_2 \overline{\boldsymbol{e}} e=i=1∑Lyt−1(i)eig(yt−1)=(1−H)⊙e+H⊙eH=W1e+W2e
y t − 1 y_{t-1} yt−1是在 t − 1 t-1 t−1时间步预测的标签概率分布, e i e_i ei是 l i l_i li的embedding。本质上就是根据概率分布对所有可能标签做加权求和。 H H H则是门控机制,控制加权embedding的比例。
实验结果
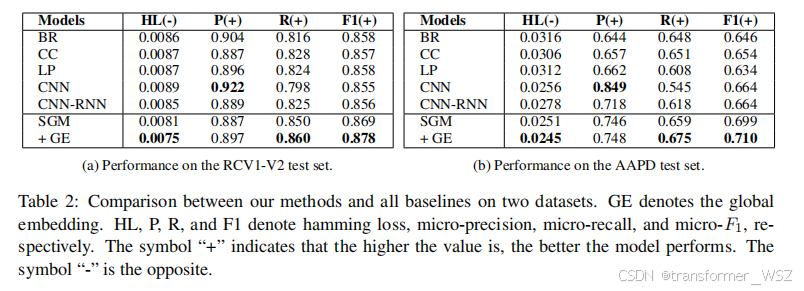
加上GE效果更加明显!
参考
- SGM
- 多标签文本分类-如何有效的利用标签之间的关系
- 多标签分类新建模方法

颜色空间转换-----将图像从 YUV 色彩空间转换为 RGB 色彩空间函数YUV2RGB())



