相关性系数和相关分析是了解变量之间关系的重要工具。通过合理选择相关性系数和科学分析数据,能够有效揭示变量之间的关系,为进一步研究和决策提供有力支持。在实际应用中,应结合业务背景、数据特性和统计原则,谨慎解释和应用相关分析结果。
相关性系数
相关性系数(Correlation Coefficient)是度量两个变量之间相关程度的统计指标。常见的相关性系数有以下几种:
-
1. 皮尔逊相关系数(Pearson Correlation Coefficient):
- 用于测量两个连续变量之间的线性相关程度。
- 取值范围为[-1, 1]:
- 1 表示完全正相关,两个变量呈线性正比例关系。
- -1 表示完全负相关,两个变量呈线性反比例关系。
- 0 表示没有线性相关关系。
- 公式:
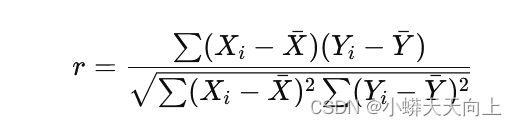
其中,Xi 和 Yi 分别为两个变量的观测值, Xˉ 和Yˉ 为变量的均值。
-
2. 斯皮尔曼相关系数(Spearman's Rank Correlation Coefficient):
- 用于测量两个变量之间的单调相关程度,适用于非线性关系或数据不满足正态分布的情况。
- 通过计算变量排名之间的皮尔逊相关系数得到。
- 公式:
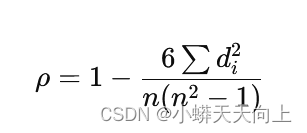
其中,di 是每对观测值排名之差,n 是观测值的数量。
-
3. 肯德尔相关系数(Kendall's Tau Coefficient):
- 另一种用于测量两个变量之间单调关系的方法,特别适用于小样本数据。
- 基于观测值对之间的一致性和不一致性计算。
- 公式:
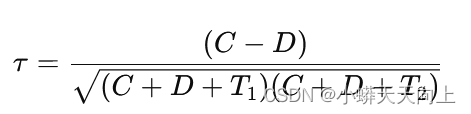
其中,C和 D 分别表示一致性和不一致性对数,T1 和 T2 分别表示两个变量的平局对数。
在Pandas库中,DataFrame.corr()方法用于计算DataFrame各列之间的相关系数。默认情况下,DataFrame.corr()使用的是皮尔逊相关系数(Pearson Correlation Coefficient)。
示例代码
以下是一个简单的示例,展示如何使用df.corr()计算DataFrame各列之间的皮尔逊相关系数:
import pandas as pd# 创建示例数据
data = {'A': [1, 2, 3, 4, 5],'B': [2, 4, 6, 8, 10],'C': [5, 4, 3, 2, 1]
}df = pd.DataFrame(data)# 计算相关系数矩阵
correlation_matrix = df.corr()
print(correlation_matrix)
输出
上述代码输出的相关系数矩阵可能如下:
A B C
A 1.000000 1.000000 -1.000000
B 1.000000 1.000000 -1.000000
C -1.000000 -1.000000 1.000000
解释
- A和B之间的相关系数为1,表示它们之间存在完全正相关关系。
- A和C之间的相关系数为-1,表示它们之间存在完全负相关关系。
- B和C之间的相关系数为-1,同样表示它们之间存在完全负相关关系。
其他相关系数方法
如果需要计算其他类型的相关系数,可以通过method参数指定,如:
method='pearson':计算皮尔逊相关系数(默认)。method='kendall':计算肯德尔相关系数。method='spearman':计算斯皮尔曼相关系数。
# 计算斯皮尔曼相关系数矩阵
spearman_corr = df.corr(method='spearman')
print(spearman_corr)
)





