聚簇索引和非聚簇索引:
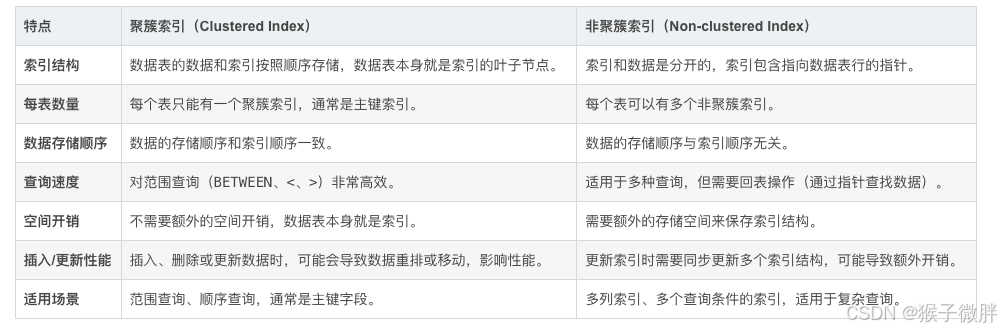
- 聚簇索引:聚簇索引是数据表的 物理顺序 和 索引顺序 一致的索引。在使用聚簇索引时,数据行本身就按照索引的顺序存储在磁盘上。也就是说,数据表的实际数据按照聚簇索引的顺序存储,这使得 每个表只能有一个聚簇索引。
- 非聚簇索引:非聚簇索引是一种 单独的索引结构,它不影响数据的物理存储顺序。非聚簇索引会将索引的 键值 和 指向数据的指针 存储在独立的存储区域。非聚簇索引的存储方式类似于书籍的 目录,索引指向数据的具体位置。
- 对比:
- 总结:
聚簇索引 是数据表的 物理顺序 和 索引顺序 一致的索引,数据行本身按索引顺序存储,适用于范围查询和顺序查询。每个表只能有一个聚簇索引,通常是主键索引。
非聚簇索引 是独立于数据表的索引结构,适用于多种查询类型。每个表可以有多个非聚簇索引,但由于需要回表操作,性能上会比聚簇索引略低。
-
小问题:主键为什么建议使用自增id?
主键最好不要使用uuid,因为uuid的值太过离散,不适合排序且可能出现新增加记录的uuid,会插入在索引树中间的位置,出现页分裂,导致索引树调整复杂度变大,消耗更多的时间和资源。
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,它会不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但如果是自增的id,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
普通索引 (常规索引)(normal):
create index idx_user_name on table(列名);
唯一索引(UNIQUE ):
对列的要求:索引列的值不能重复
多个二级索引的组合使用:
一张表分别有a,b,c三个字段增加索引,d无索引;
- a=条件:先通过索引a检索出符合条件的id,然后回表查询数据;(会使用一个索引)
- a=条件 and b=条件 and c=条件 :先通过索引a检索出符合条件的id,然后回表根据剩余条件检索结果;(只会使用一个索引)
- a=条件1 or a=条件2:会使用一个索引
- a=条件1 or b=条件2:先通过索引a检索出符合条件的id进行缓存,再通过索引b检索出符合条件的id,再和第一步的记过进行并集操作;(这个过程叫【索引合并】当检索条件有or但是所有的条件都有索引时,索引不失效,可以走【两个索引】)
- a=条件 and b=条件 and d=条件3:先通过索引a检索出符合条件的id,然后回表查询数据;(会使用一个索引)
- a=条件 or b=条件 or d=条件3:优化器发现【d】无索引,同时连接的逻辑是【or】没有办法利用【索引】优化,只能全表扫描,索引失效。
(发生全表扫描,索引失效,条件中有没建立索引的列,同时关联条件是or)
复合索引(联合索引):
- 当【查询语句】中包含【多个查询条件,且查询的顺序基本保持一致】时,我们推荐使用复合索引,索引的【组合使用】效率是低于【复合索引】的。
- 比如:我们经常按照A列、B列、C列进行查询时,通常的做法是建立一个由三个列共同组成的【复合索引】而不是对每一个列建立【普通索引】。
创建索引:create index idx_a_b_c on t. ble. (a,b,c);
- a=条件 and b=条件:
第一步:通过【a】检索出所有符合条件d叶子节点。
第二步:在【满足上一步条件的叶子节点中】查询价格在1万到3万之间的包包的列,查询出对应的id,回表查询列数据。
结论:会使用复合索引的两个部分。
-
a=条件 or b=条件:
第一步:优化器发现我们并没有一个【a】的单独的二级索引,此时要查询,必须进行全表扫描。
结论:但凡查询的条件中没有【复合索引的第一部分】,索引直接【失效】,全表扫描。
-
a=条件 and b=条件 and d=条件:
第一步:通过【a】检索出所有叶子节点。
第二步:在【满足上一步条件的叶子节点中】查询【b】包的叶子节点。
第三步:因为【d】无索引,但是是【and】的关系,我们只需要将上一步得到的结果回表查询,在这个很小的范围内,检索d条件即可。
-
条件1<a<条件2 and 条件3<b<条件4:
第一步:通过【品牌索引】检索出【a】所有叶子节点。
第二步:我们本想在第一步的结果中,快速定位【b】范围,但是发现一个问题,由于第一步不是等值查询,会导致后边的结果不连续,必须对【上一步的结果】全部遍历,才能拿到对应的结果。
结论:只会使用复合索引的第一个部分,这个就引出了【复合索引中特别重要的一个概念】-【最左前缀原则】。
结论:只会使用复合索引的第一个部分,这个就引出了【复合索引中特别重要的一个概念】-【最左前缀原则】。
重点:最左前缀原则:
(1)最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 ,如果建立(a,b,c,d)顺序的联合索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
(2)= 和 in 可以乱序,比如a = 1 and b < 2 and c = 3 ,咱们建立的索引就可以是(a,c,b)或者(c,a,b)。
全文索引(FULLTEXT):
做全文检索使用的索引,但是这种场景,我们有更好的替代品,如:ElacticSearch
索引问题:
哪些情况下适合建索引
- 频繁作为where条件语句查询的字段
- 关联字段需要建立索引
- 分组,排序字段可以建立索引
- 统计字段可以建立索引,例如count(),max()等
哪些情况下不适合建索引
-
频繁更新的字段不适合建立索引
-
where条件中用不到的字段不适合建立索引
-
表数据可以确定比较少的不需要建索引
-
数据重复且发布比较均匀的的字段不适合建索引(唯一性太差的字段不适合建立索引),例如性别,真假值
-
参与列计算的列不适合建索引,索引会失效
能用复合索引的要使用复合索引
null值也是可以走索引的,他被处理成最小值放在b+树的最左侧
使用短索引
对字符串的列创建索引,如果可能,应该指定一个前缀长度。例如,如果有一个CHAR(255)的 列,如果在前10 个或20 个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
排序的索引问题
mysql查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要,最好给这些列创建复合索引。
MySQL索引失效的几种情况:
- 如果条件中有or,即使其中有条件带索引也不会使用走索引,除非全部条件都有索引
- 复合索引不满足最左原则就不能使用全部索引
- like查询
- 存在列计算
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引,比如结果的量很大
- 隐式类型转换:本来是字符串,你使用数字和他比较



:EtherCAT运动控制器的高效加工指令自定义封装)

)
