学AI还能赢奖品?每天30分钟,25天打通AI任督二脉 (qq.com)
网络构建
神经网络模型是由神经网络层和Tensor操作构成的,mindspore.nn提供了常见神经网络层的实现,在MindSpore中,Cell类是构建所有网络的基类,也是网络的基本单元。一个神经网络模型表示为一个Cell,它由不同的子Cell构成。使用这样的嵌套结构,可以简单地使用面向对象编程的思维,对神经网络结构进行构建和管理。
下面我们将构建一个用于Mnist数据集分类的神经网络模型。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14import mindspore
from mindspore import nn, ops定义模型类
当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。
construct意为神经网络(计算图)构建,相关内容详见使用静态图加速。
class Network(nn.Cell):def __init__(self):super().__init__()self.flatten = nn.Flatten()self.dense_relu_sequential = nn.SequentialCell(nn.Dense(28*28, 512, weight_init="normal", bias_init="zeros"),nn.ReLU(),nn.Dense(512, 512, weight_init="normal", bias_init="zeros"),nn.ReLU(),nn.Dense(512, 10, weight_init="normal", bias_init="zeros"))def construct(self, x):x = self.flatten(x)logits = self.dense_relu_sequential(x)return logits构建完成后,实例化Network对象,并查看其结构。
model = Network()
print(model)我们构造一个输入数据,直接调用模型,可以获得一个十维的Tensor输出,其包含每个类别的原始预测值。
model.construct()方法不可直接调用。
X = ops.ones((1, 28, 28), mindspore.float32)
logits = model(X)
# print logits
logits在此基础上,我们通过一个nn.Softmax层实例来获得预测概率。
pred_probab = nn.Softmax(axis=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")使用nn.Cell作为基类来定义自己的神经网络模型Network。在__init__方法中初始化所需的神经网络层,并在construct方法中定义前向传播过程。
实例化自定义的网络类Network,调用模型实例model处理输入数据X,得到预测输出logits。通过nn.Softmax转换为各分类的概率。
模型层
本节中我们分解上节构造的神经网络模型中的每一层。首先我们构造一个shape为(3, 28, 28)的随机数据(3个28x28的图像),依次通过每一个神经网络层来观察其效果。
input_image = ops.ones((3, 28, 28), mindspore.float32)
print(input_image.shape)nn.Flatten
实例化nn.Flatten层,将28x28的2D张量转换为784大小的连续数组。
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.shape)nn.Dense
nn.Dense为全连接层,其使用权重和偏差对输入进行线性变换。
layer1 = nn.Dense(in_channels=28*28, out_channels=20)
hidden1 = layer1(flat_image)
print(hidden1.shape)nn.ReLU¶
nn.ReLU层给网络中加入非线性的激活函数,帮助神经网络学习各种复杂的特征。
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")nn.SequentialCell¶
nn.SequentialCell是一个有序的Cell容器。输入Tensor将按照定义的顺序通过所有Cell。我们可以使用SequentialCell来快速组合构造一个神经网络模型。
seq_modules = nn.SequentialCell(flatten,layer1,nn.ReLU(),nn.Dense(20, 10)
)logits = seq_modules(input_image)
print(logits.shape)nn.Softmax¶
最后使用nn.Softmax将神经网络最后一个全连接层返回的logits的值缩放为[0, 1],表示每个类别的预测概率。axis指定的维度数值和为1。
softmax = nn.Softmax(axis=1)
pred_probab = softmax(logits)nn.Flatten展平输入数据,nn.Dense全连接层,nn.ReLU非线性激活函数,nn.SequentialCell有序地组合这些层,形成一个完整的网络结构。nn.Softmax将网络的原始输出转换为概率分布,以进行分类预测。
模型参数
网络内部神经网络层具有权重参数和偏置参数(如nn.Dense),这些参数会在训练过程中不断进行优化,可通过 model.parameters_and_names() 来获取参数名及对应的参数详情。
print(f"Model structure: {model}\n\n")for name, param in model.parameters_and_names():print(f"Layer: {name}\nSize: {param.shape}\nValues : {param[:2]} \n")更多内置神经网络层详见mindspore.nn API。
查看模型的结构和参数详情。
面向对象编程: 利用MindSpore的nn.Cell基类,使用面向对象的编程风格来构建和管理网络结构。
模块化: 将不同的神经网络层封装成模块,灵活地组合和重用这些模块组合成完整的网络。
调试和可视化: 查看每层的输出和参数对于调试和理解模型有帮助。
函数式自动微分
神经网络的训练主要使用反向传播算法,模型预测值(logits)与正确标签(label)送入损失函数(loss function)获得loss,然后进行反向传播计算,求得梯度(gradients),最终更新至模型参数(parameters)。自动微分能够计算可导函数在某点处的导数值,是反向传播算法的一般化。自动微分主要解决的问题是将一个复杂的数学运算分解为一系列简单的基本运算,该功能对用户屏蔽了大量的求导细节和过程,大大降低了框架的使用门槛。
MindSpore使用函数式自动微分的设计理念,提供更接近于数学语义的自动微分接口grad和value_and_grad。下面我们使用一个简单的单层线性变换模型进行介绍。
%%capture captured_output
# 实验环境已经预装了mindspore==2.2.14,如需更换mindspore版本,可更改下面mindspore的版本号
!pip uninstall mindspore -y
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindspore==2.2.14import numpy as np
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore import Tensor, Parameter函数与计算图
计算图是用图论语言表示数学函数的一种方式,也是深度学习框架表达神经网络模型的统一方法。我们将根据下面的计算图构造计算函数和神经网络。
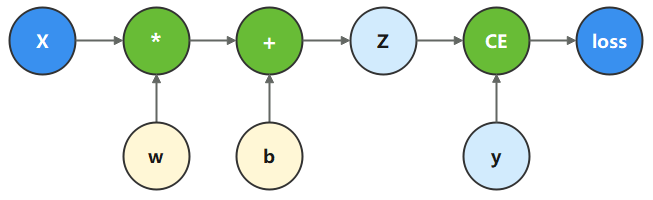
在这个模型中,𝑥为输入,𝑦为正确值,𝑤和𝑏是我们需要优化的参数。
x = ops.ones(5, mindspore.float32) # input tensor
y = ops.zeros(3, mindspore.float32) # expected output
w = Parameter(Tensor(np.random.randn(5, 3), mindspore.float32), name='w') # weight
b = Parameter(Tensor(np.random.randn(3,), mindspore.float32), name='b') # bias我们根据计算图描述的计算过程,构造计算函数。 其中,binary_cross_entropy_with_logits 是一个损失函数,计算预测值和目标值之间的二值交叉熵损失。
def function(x, y, w, b):z = ops.matmul(x, w) + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))return lossloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z)) 后面2个参数ops.ones_like(z), ops.ones_like(z)对应的应该是weight=None和pos_weight=None,每个样本的损失会乘以相应的权重,设置成ops.ones_like(z),和ops.ones_like(z)意味着每个样本的损失将被平等地加权,因为没有为任何样本指定不同的权重。
执行计算函数,可以获得计算的loss值。
loss = function(x, y, w, b)
print(loss)根据计算图构造计算函数和神经网络。定义损失函数(二值交叉熵)计算预测值与目标值之间的损失。
微分函数与梯度计算¶
为了优化模型参数,需要求参数对loss的导数:和
,此时我们调用
mindspore.grad函数,来获得function的微分函数。
这里使用了grad函数的两个入参,分别为:
fn:待求导的函数。grad_position:指定求导输入位置的索引。
由于我们对𝑤和𝑏求导,因此配置其在function入参对应的位置(2, 3)。
使用
grad获得微分函数是一种函数变换,即输入为函数,输出也为函数。
grad_fn = mindspore.grad(function, (2, 3))执行微分函数,即可获得𝑤、𝑏对应的梯度。
grads = grad_fn(x, y, w, b)
print(grads)使用MindSpore的grad函数,获得指定参数位置grad_position的梯度。
Stop Gradient¶
通常情况下,求导时会求loss对参数的导数,因此函数的输出只有loss一项。当我们希望函数输出多项时,微分函数会求所有输出项对参数的导数。此时如果想实现对某个输出项的梯度截断,或消除某个Tensor对梯度的影响,需要用到Stop Gradient操作。
这里我们将function改为同时输出loss和z的function_with_logits,获得微分函数并执行。
def function_with_logits(x, y, w, b):z = ops.matmul(x, w) + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))return loss, zgrad_fn = mindspore.grad(function_with_logits, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)可以看到求得𝑤、𝑏对应的梯度值发生了变化。此时如果想要屏蔽掉z对梯度的影响,即仍只求参数对loss的导数,可以使用ops.stop_gradient接口,将梯度在此处截断。我们将function实现加入stop_gradient,并执行。
def function_stop_gradient(x, y, w, b):z = ops.matmul(x, w) + bloss = ops.binary_cross_entropy_with_logits(z, y, ops.ones_like(z), ops.ones_like(z))return loss, ops.stop_gradient(z)grad_fn = mindspore.grad(function_stop_gradient, (2, 3))
grads = grad_fn(x, y, w, b)
print(grads)可以看到,求得𝑤、𝑏对应的梯度值与初始function求得的梯度值一致。
阻止某个Tensor对梯度的影响,可以使用ops.stop_gradient接口来实现梯度的截断。
Auxiliary data
Auxiliary data意为辅助数据,是函数除第一个输出项外的其他输出。通常我们会将函数的loss设置为函数的第一个输出,其他的输出即为辅助数据。
grad和value_and_grad提供has_aux参数,当其设置为True时,可以自动实现前文手动添加stop_gradient的功能,满足返回辅助数据的同时不影响梯度计算的效果。
下面仍使用function_with_logits,配置has_aux=True,并执行。
grad_fn = mindspore.grad(function_with_logits, (2, 3), has_aux=True)grads, (z,) = grad_fn(x, y, w, b)
print(grads, z)可以看到,求得𝑤、𝑏对应的梯度值与初始function求得的梯度值一致,同时z能够作为微分函数的输出返回。
在微分函数grad中,除了主要的输出(如loss)之外,还可能有其他的辅助输出。使用has_aux参数可以满足返回辅助数据的同时不影响梯度计算。
神经网络梯度计算
前述章节主要根据计算图对应的函数介绍了MindSpore的函数式自动微分,但我们的神经网络构造是继承自面向对象编程范式的nn.Cell。接下来我们通过Cell构造同样的神经网络,利用函数式自动微分来实现反向传播。
首先我们继承nn.Cell构造单层线性变换神经网络。这里我们直接使用前文的𝑤𝑤、𝑏𝑏作为模型参数,使用mindspore.Parameter进行包装后,作为内部属性,并在construct内实现相同的Tensor操作。
# Define model
class Network(nn.Cell):def __init__(self):super().__init__()self.w = wself.b = bdef construct(self, x):z = ops.matmul(x, self.w) + self.breturn z接下来我们实例化模型和损失函数。
# Instantiate model
model = Network()
# Instantiate loss function
loss_fn = nn.BCEWithLogitsLoss()完成后,由于需要使用函数式自动微分,需要将神经网络和损失函数的调用封装为一个前向计算函数。
# Define forward function
def forward_fn(x, y):z = model(x)loss = loss_fn(z, y)return loss完成后,我们使用value_and_grad接口获得微分函数,用于计算梯度。
由于使用Cell封装神经网络模型,模型参数为Cell的内部属性,此时我们不需要使用grad_position指定对函数输入求导,因此将其配置为None。对模型参数求导时,我们使用weights参数,使用model.trainable_params()方法从Cell中取出可以求导的参数。
grad_fn = mindspore.value_and_grad(forward_fn, None, weights=model.trainable_params())loss, grads = grad_fn(x, y)
print(grads)执行微分函数,可以看到梯度值和前文function求得的梯度值一致。
基于nn.Cell的神经网络模型,可以使用value_and_grad接口结合模型的trainable_params()方法来计算梯度。
自动微分:自动微分简化了梯度计算过程,让开发者可以专注于模型设计而非复杂的数学推导。MindSpore通过value_and_grad和grad支持面向对象的模型定义(继承nn.Cell)和函数式自动微分。
计算图:计算图以图形方式表示了函数的运算流程,使得自动微分能够按图进行反向传播。
梯度计算:MindSpore允许对特定的函数输入位置进行梯度计算(通过grad_position参数),并且提供了ops.stop_gradient来控制哪些部分参与梯度计算。通过has_aux=True,可以在计算梯度的同时返回辅助数据。

数的定义与基本术语)



