摘要
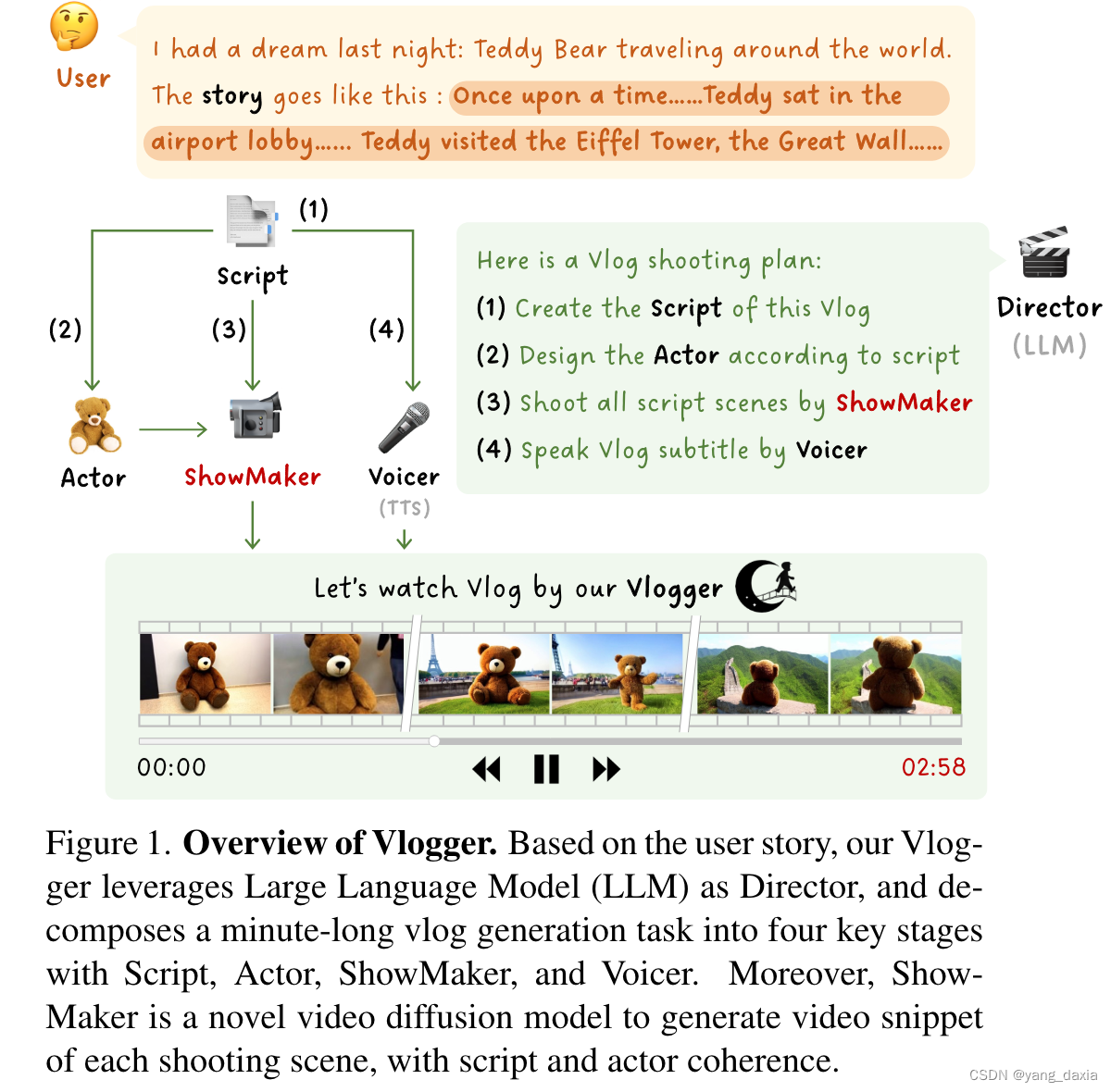
论文介绍了一个名为“Vlogger”的通用人工智能系统,它能够根据用户的描述生成分钟级的视频博客(vlog)。与通常只有几秒钟的短视频不同,vlog通常包含复杂的故事情节和多样化的场景,这对现有的视频生成方法来说是一个挑战。为了突破这一瓶颈,Vlogger系统巧妙地利用了大型语言模型(LLM)作为导演,将长篇视频生成任务分解为四个关键阶段,每个阶段都调用不同的基础模型来扮演vlog专业人员的关键角色,包括:
- 剧本(Script):使用LLM根据用户故事创建剧本,描述多个拍摄场景及其相应的拍摄时长。
- 演员(Actor):根据剧本总结角色,并使用角色设计师生成这些角色的参考图像。
- 秀场制作者(ShowMaker):作为摄像师,根据剧本文本和角色图像生成每个拍摄场景的视频片段,并有效增强片段的空间-时间连贯性。
- 旁白(Voicer):最后,LLM导演调用配音员为vlog配音,将剧本字幕转化为音频。
Vlogger系统的核心是ShowMaker,这是一个视频扩散模型,通过结合剧本和演员的注意力作为文本和视觉提示,可以生成具有控制时长的视频片段。此外,Vlogger设计了一个简洁的混合训练范式,通过文本到视频(T2V)生成和预测的混合训练来提升ShowMaker在这两种任务上的能力。
通过广泛的实验,该方法在零样本T2V生成和预测任务上达到了最先进的性能。更重要的是,Vlogger能够从开放世界的描述中生成超过5分钟的vlog,且在剧本和角色的视频连贯性上没有损失。
方法
框架
top-down planning自顶向下的规划

剧本创建(Script Creating):
初始阶段,大型语言模型(LLM)作为导演,将用户的故事转换成一个基本的剧本草稿。然后,通过粗到细的指令,LLM逐步细化剧本,包括添加故事细节、完善剧本结构、检查是否有遗漏的重要部分,以及为每个场景分配拍摄时长。
角色设计(Actor Designing):
创建剧本后,LLM再次阅读剧本以总结角色列表,并调用角色设计师生成这些角色的参考图像。
角色设计师使用Stable Diffusion XL等工具根据角色描述生成高质量的角色图像。
主角选择(Protagonist Selection):
根据剧本和角色列表,LLM决定每个拍摄场景的主角(即主演)。
场景规划(Scene Scheduling):
LLM为剧本中的每个场景分配拍摄时长,确保视频的总时长符合预期。
Bottom-Up Shooting自底向上的拍摄
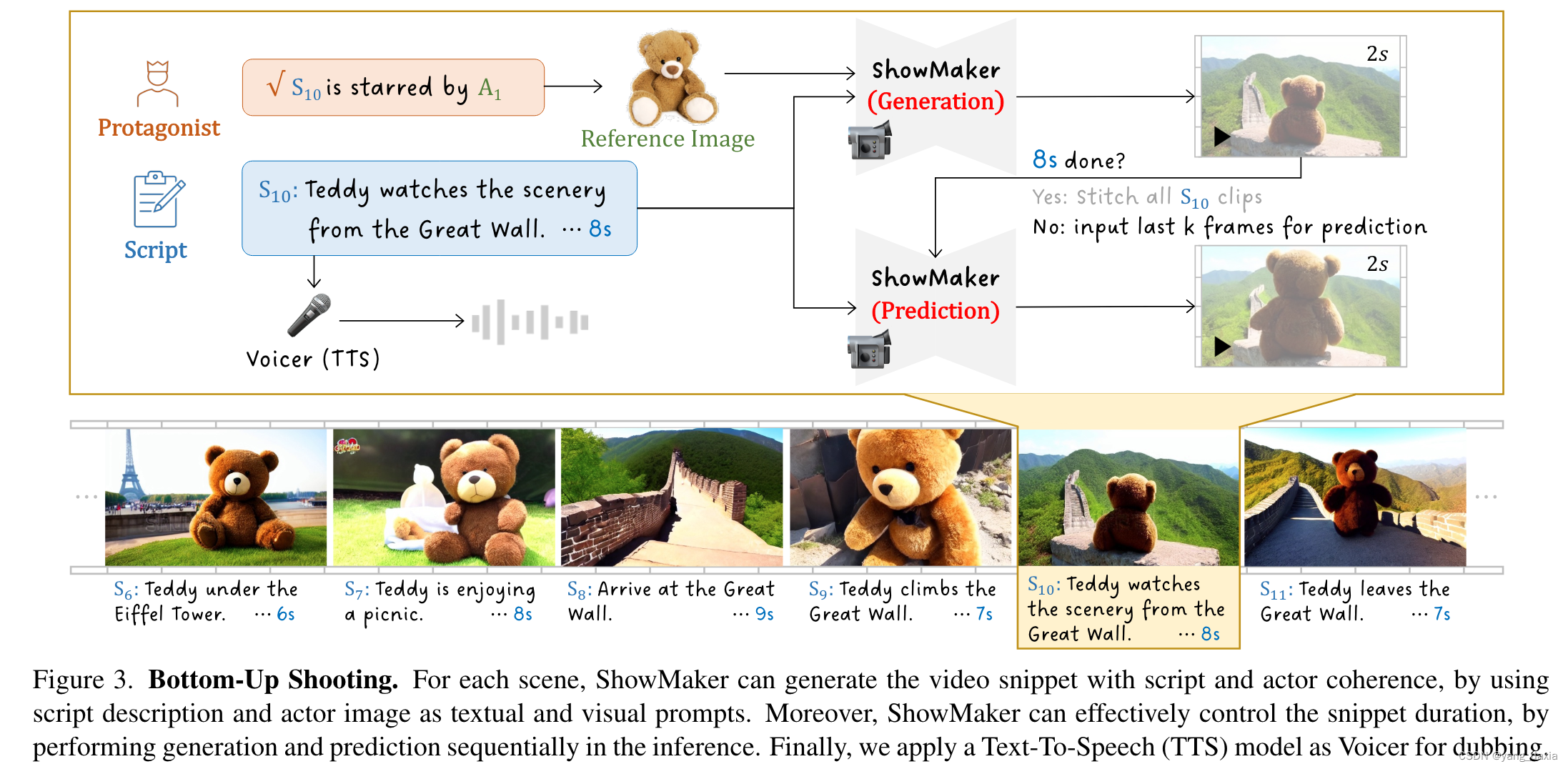
ShowMaker 拍摄
使用新提出的ShowMaker作为摄像师(视频扩散模型),可以根据每个拍摄场景的剧本描述和角色图像生成视频片段。如果生成的视频片段时长小于剧本中分配的时长,ShowMaker继续利用当前片段的最后几帧作为上下文,生成下一个片段,直到生成的视频片段总时长达到剧本分配的时长。最后将所有生成的片段组合成场景的视频片段。
Voicer 配音
使用Text-To-Speech(TTS)模型作为Voicer,将剧本描述转换成相应的音频。最后将生成的音频添加到对应的视频片段上,形成有声视频片段。
showmaker摄影师
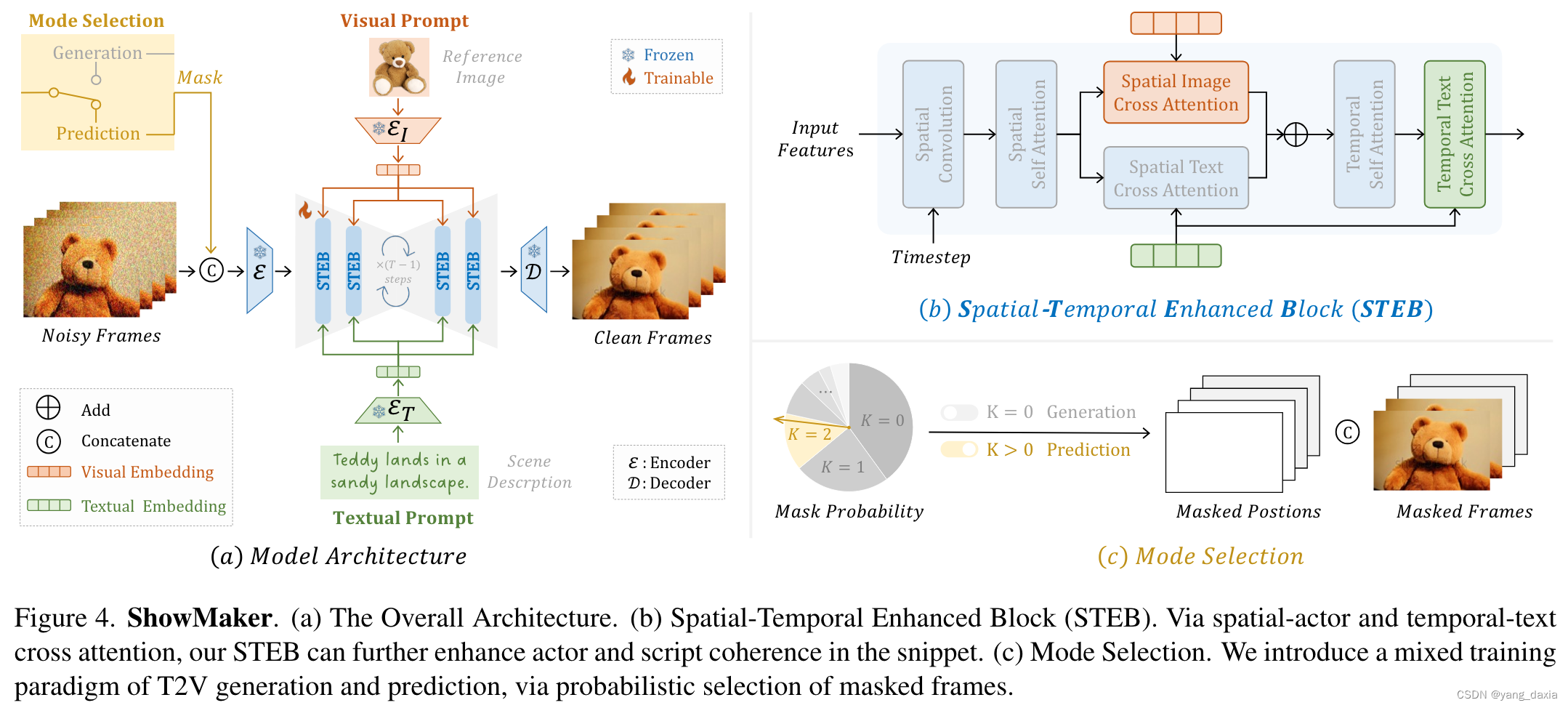
ShowMaker 是一个视频扩散模型。1、将带噪的训练片段送入自编码器的编码器提取其潜在代码。2、去噪阶段:将潜在代码从带噪的潜在代码中重建出来。使用文本与actor控制生产内容,选择器选择模式。
空间-时间增强块(Spatial-Temporal Enhanced Block, STEB)
- 空间操作:包括卷积(CV)、自我注意力(SA)和空间交叉注意力(CA),用于独立编码片段中的每一帧。
- 空间图像交叉注意力:使用主角的参考图像作为视觉上下文,增强空间嵌入。
- 时间操作:执行自我注意力沿着时间维度,学习片段中帧之间的相关性。
- 时间文本交叉注意力:使用场景描述作为文本上下文,增强时间编码。
混合训练范式与模式选择(Mixed Training Paradigm with Mode Selection)
ShowMaker 旨在生成具有剧本分配时长的视频片段,它通过生成和预测模式的结合来实现这一点。
- 模式选择机制:设计一种概率性的选择方式,选择干净片段的k帧作为带噪片段的上下文,从而选择是使用生成模式还是预测模式。
- 如果生成的视频片段时长小于剧本中分配的时长,ShowMaker 将继续执行预测模式,使用当前片段的最后k帧作为上下文,生成下一个片段。
训练过程:通过在训练过程中结合生成(k=0)和预测(k>0)模式,ShowMaker 学会了如何生成和预测视频片段。

正式发布:鸿蒙诞生以来最大升级,碰一碰、小艺圈选重磅上线)


