标题:[MySQL初阶]MySQL(8)索引机制:下
@水墨不写bug

文章目录
- 四、从问题到底层,从现象到本质
- 1.为什么插入的数据默认排好序
- 2.MySQL的Page
- (1)为什么选择用Page?
- (2)单个Page的结构
- (3)Mysql的多个Page调联
四、从问题到底层,从现象到本质
1.为什么插入的数据默认排好序
创建如下的一张表:
create table if not exists user (
id int primary key,
age int not null,
name varchar(16) not null
);
并且按照如下的顺序插入几条数据:
insert into user (id, age, name) values(3, 18, '孙悟空');
insert into user (id, age, name) values(4, 16, '哪吒');
insert into user (id, age, name) values(2, 26, '李小龙');
insert into user (id, age, name) values(5, 36, '成龙');
insert into user (id, age, name) values(1, 56, '奶龙');
插入完成后,查询表中的数据,会发现数据已经被按照id排好序了,这是为什么?
 想要理解这个问题,就需要先明白MySQL的Page到底是什么:
想要理解这个问题,就需要先明白MySQL的Page到底是什么:
2.MySQL的Page
(1)为什么选择用Page?
**IO低效的最主要矛盾不是单次IO的数据量的大小,而是IO的次数。**其次,根据局部性原理,每次IO都加载一个page,相当于预加载的一些数据,如果下次访问的数据刚好已经被加载到内存,这样效率反而可以得到提升。
(2)单个Page的结构
单个page的结构如下:
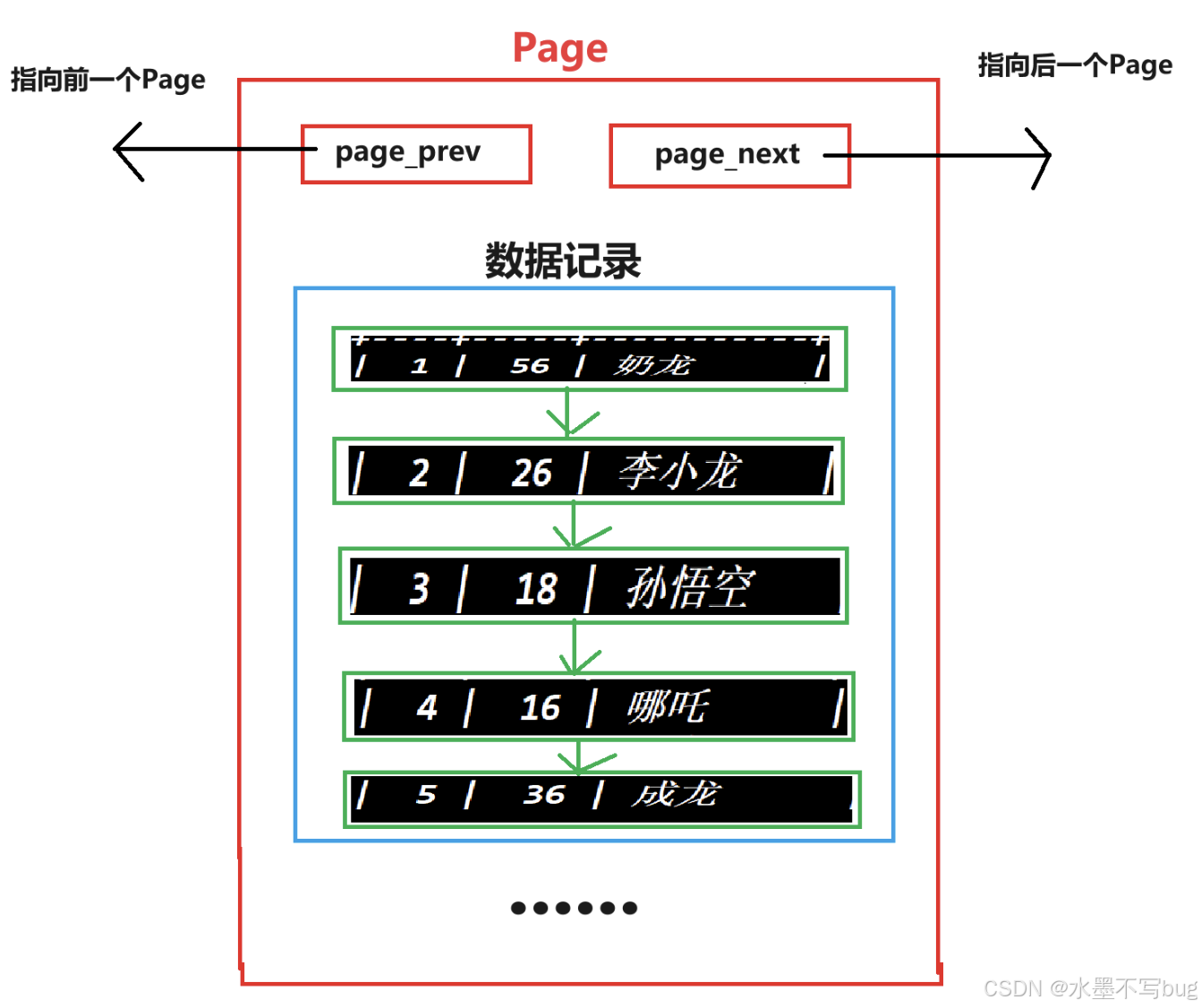 不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 构成双向链表。
不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 构成双向链表。
因为有主键的问题, MySQL 会默认按照主键给我们的数据进行排序;如果没有指定主键,那么默认就会按照插入的顺序进行存储。
这就解释了为什么我们插入的数据会按照id进行排序:因为id被设置为主键。
为什么要排序?
为什么要对插入的数据进行排序?本质是为了优化查询效率。
页内部存放数据的模块,实质上也是一个链表的结构,链表的特点也就是增删快,查询修改慢,所以优化查询效率是当务之急。
正式因为有序,在查找的时候,从头到后都是有效查找,没有任何一个查找是浪费的,而且,如果运气好,是可以提前结束查找过程的!
总结:
page内数据的有序结构以及有序查找运气好可以提前结束的特性,决定了一种新的数据结构的诞生:B+树。
(3)Mysql的多个Page调联
~完
转载请注明出处






