为什么 MySQL 选择使用 B+ 树作为索引结构
- 一、 B+树的结构特点
- B+树图示
- 二、 B+树的性能优势
- 1. 磁盘I/O效率
- 2. 高效的范围查询
- 3. 对大数据量的高效处理
- 4. 支持多种查询操作
- 5. 适应频繁的增删改操作
- 三、 与其他索引结构的对比
- 1. B树 vs B+树
- 2. 哈希索引 vs B+树
- 四、 MySQL使用B+树的应用场景
- 总结
MySQL选择使用B+树作为索引结构主要是因为B+树在数据存储、查询优化、范围查询等方面具有显著优势。
一、 B+树的结构特点
B+树是一种自平衡的多路查找树,它的特点包括:
- 所有数据都存储在叶子节点:B+树的内部节点仅存储键值和指向子节点的指针,而叶子节点存储了数据的实际值。这使得B+树的内节点更加精简,能够提高查询时的效率。
- 叶子节点按顺序链表连接:B+树的所有叶子节点通过指针链接成一个链表,因此支持高效的顺序访问。这种结构使得在进行范围查询时,B+树能以较小的代价顺序访问所有符合条件的数据。
B+树图示
以下是一棵 B+ 树的典型结构(图源网络,侵删):
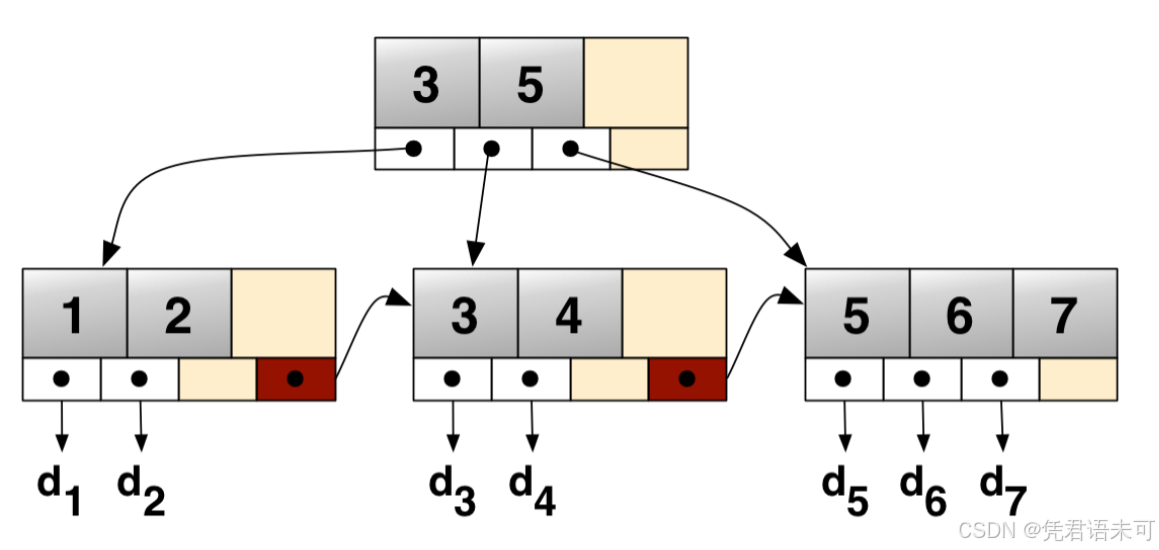
二、 B+树的性能优势
1. 磁盘I/O效率
-
减少磁盘访问次数:B+树的高度通常较低,每个节点存储多个指针和键值。这意味着B+树能够将树的高度保持得比较低,从而减少了查询时的磁盘访问次数。特别是在处理大数据量时,这一点尤为重要。B+树的节点大小通常与磁盘块的大小匹配,因此一次访问一个磁盘块可以访问到多个键值,降低了磁盘I/O的开销。
-
顺序存取叶子节点:B+树的叶子节点通过指针链表连接,因此可以顺序访问叶子节点,避免了额外的磁盘读取操作,特别适合于范围查询等顺序扫描的操作。
2. 高效的范围查询
-
顺序访问优势:由于B+树的叶子节点按顺序排列,并且通过指针链表连接,进行范围查询时可以从起始位置开始,沿着链表顺序读取所有符合条件的元素,而不需要回到树的其他部分。比如,对于
WHERE column BETWEEN x AND y这样的查询,B+树可以高效地定位到x并顺序扫描至y,而不需要多次跳转树的不同层级。 -
支持区间查找:B+树支持查找区间内的数据,且能够在不重新遍历整个树的情况下通过顺序扫描叶子节点来完成范围查询,极大提高了性能。
3. 对大数据量的高效处理
-
低高度的树结构:B+树的高度通常较低,树的每一层都包含多个指针(分支因子大)。这使得B+树适合存储在磁盘上,减少了磁盘I/O操作。查询时只需要较少的树层查找,大大提高了查询效率。
-
高效的查询时间复杂度:B+树的查找时间复杂度是O(log N),因为它是自平衡的树结构。在最坏的情况下,查询操作最多需要查找树的高度,这个高度与节点的数量成对数关系,保证了查询的高效性。
4. 支持多种查询操作
-
等值查询和范围查询:B+树支持常见的等值查询(例如
WHERE column = x)和范围查询(例如WHERE column BETWEEN x AND y)。由于B+树的叶子节点通过链表连接,范围查询的时间复杂度接近O(K),其中K是结果集的大小。 -
前缀匹配和模糊查询:对于如
LIKE操作等前缀匹配查询,B+树也表现出较好的性能,能够高效地定位到匹配的范围。
5. 适应频繁的增删改操作
-
自动平衡:B+树是一种自平衡的数据结构,在插入和删除节点时,B+树能够保持平衡,保证查询操作的时间复杂度为O(log N)。在频繁进行插入和删除操作的数据库环境下,B+树能够有效避免树结构失衡而导致性能下降。
-
内存与磁盘的适配:B+树的节点较大,每个节点可以容纳多个键值,因此适合存储在磁盘上,而内存中可以缓存一部分树结构以提高查询速度。B+树的这种特性使得它能够处理大规模的数据集。
三、 与其他索引结构的对比
1. B树 vs B+树
-
数据存储位置:在B树中,数据存储在内节点和叶子节点中,而在B+树中,数据只存储在叶子节点中,内节点仅存储索引。这使得B+树的内节点更加精简,有利于提高查询性能。
-
叶子节点的链表结构:B+树叶子节点按顺序连接成链表,适合范围查询,而B树没有这种结构。
2. 哈希索引 vs B+树
-
哈希索引:哈希索引通常只适合等值查询,不能用于范围查询,而B+树不仅能支持等值查询,还能高效支持范围查询。
-
B+树:B+树适合于大规模数据存储,并能提供多种查询操作,包括等值查询、范围查询和前缀匹配查询,此外,B+树的查询时间复杂度为O(log N),对于范围查询更是具有优势。
四、 MySQL使用B+树的应用场景
-
InnoDB存储引擎的默认索引结构:InnoDB存储引擎使用B+树作为其默认的聚簇索引结构。这意味着数据表的所有行数据按B+树的顺序存储,主键索引就是B+树索引。
-
二级索引:InnoDB的二级索引(非聚簇索引)也是基于B+树实现的。非聚簇索引将索引键和对应的数据行的主键值一起存储,而主键索引则在叶子节点存储数据行本身。
-
高效的检索和更新:B+树支持快速的插入、删除和更新操作。在MySQL中,特别是对于大量数据的应用,B+树的自平衡特性保证了系统能够在高并发情况下维持高效的性能。
总结
MySQL选择B+树作为索引结构,是因为B+树能够在磁盘存储环境中提供高效的查询性能。它的自平衡特性、支持高效的范围查询、减少磁盘I/O操作以及能够处理大规模数据集的能力,使其成为关系数据库索引的理想选择。B+树在处理频繁的增删改查操作、提高数据访问速度以及范围查询时表现出色,这些特点都符合MySQL数据库系统的需求。
MySQL选择使用B+树作为索引结构的原因主要包括以下几点:
高效的范围查询:B+树是一种自平衡的树结构,所有的叶子节点都在同一层,因此支持高效的范围查询。因为在B+树中,叶子节点通过指针连接起来,范围查询时只需要顺序扫描叶子节点,避免了重新遍历树的过程。
更高的磁盘I/O效率:B+树的节点存储了指向子节点的指针,而且叶子节点通过链表连接,这使得它非常适合磁盘存储。每个节点一般较大,可以存储更多的元素,从而减少了磁盘I/O的次数。B+树的多级索引结构有助于减少需要访问的磁盘块数。
支持顺序访问:由于B+树的叶子节点是按顺序排列的,并且通过链表连接,因此B+树非常适合需要顺序遍历的场景,比如
ORDER BY查询或范围查询。优化查询性能:B+树的每个节点都存储了键值和指向下一层节点的指针。通过这种方式,B+树能在对大量数据进行查找时,保持O(log N)的时间复杂度,能快速定位到对应的数据。
支持多种查询操作:B+树能够支持各种类型的查询操作,包括等值查询、范围查询、前缀匹配等,且在这些操作中都能够表现出较高的性能。
易于维护:B+树自平衡的特点意味着它能够自动调整自身的结构,避免了因数据变化导致的性能下降。对于频繁插入和删除操作的数据库,B+树能够保证始终保持较好的查询性能。



)
)