一、CUDA内存模型概述
1. CUDA内存模型
对于程序员来说,一般有两种类型的存储器:
· 可编程的:你需要显式地控制哪些数据存放在可编程内存中
· 不可编程的:你不能决定数据的存放位置,程序将自动生成存放位置以获得良好的性能
在CPU内存层次结构中,一级缓存和二级缓存都是不可编程的存储器。
CUDA内存模型提出了多种可编程内存的类型:寄存器、共享内存、本地内存、常量内存、纹理内存、全局内存。
一个核函数中的线程都有自己私有的本地内存。一个线程块有自己的共享内存,对同一线程块中所有线程都可见,其内容持续线程块的整个生命周期。所有线程都可以访问全局内存。所有线程都能访问的只读内存空间有:常量内存空间和纹理内存空间。全局内存、常量内存和纹理内存空间有不同的用途。纹理内存为各种数据布局提供了不同的寻址模式和滤波模式。

寄存器
寄存器是GPU上运行速度最快的内存空间。核函数中声明的一个没有其他修饰符的自变量,通常存储在寄存器中。在核函数声明的数组中,如果用于引用该数组的索引是常量且能在编译时确定,那么该数组也存储在寄存器中。
寄存器变量对于每个线程来说都是私有的,一个核函数通常使用寄存器来保存需要频繁访问的线程私有变量。寄存器变量与核函数的生命周期相同。一旦核函数执行完毕,就不能对寄存器变量进行访问了。
如果一个核函数使用了超过硬件限制数量的寄存器,则会用本地内存替代多占用的寄存器。这种寄存器溢出会给性能带来不利影响。nvcc编译器使用启发式策略来最小化寄存器的使用,以避免寄存器溢出。
本地内存

共享内存
在核函数中使用如下修饰符修饰的变量存放在共享内存中:__shared__
共享内存在核函数的范围内声明,其生命周期伴随着整个线程块。当一个线程块执行结束后,其分配的共享内存将被释放并重新分配给其他线程块。
共享内存是线程之间相互通信的基本方式。一个块内的线程通过使用共享内存中的数据可以相互合作。访问共享内存必须同步使用如下调用:
void __syncthreads();该函数设立了一个执行障碍点,即同一个线程块中的所有线程必须在其他线程被允许执行前达到该处。为线程块中所有线程设立障碍点,这样可以避免潜在的数据冲突。

常量内存
常量内存驻留在设备内存中,并在每个SM专用的常量缓存中缓存。常量变量用如下修饰符来修饰:__constant__
常量变量必须在全局空间内和所有核函数之外进行声明。对于所有计算能力的设备,都只可以声明64KB的常量内存。常量内存是静态声明的,并对同一编译单元中的所有核函数可见。
核函数只能从常量内存中读取数据。因此,常量内存必须在主机端使用下面的函数来初始化:
cudaError_t cudaMemcpyToSymbol(const void* symbol, const void* src, size_t count);这个函数将count个字节从src指向的内存复制到symbol指向的内存中,这个变量存放在设备的全局内存或常量内存中。在大多数情况下这个函数是同步的。
每从一个常量内存中读取一次数据,都会广播给线程束里的所有线程。
纹理内存
纹理内存驻留在设备内存中,并在每个SM的只读缓存中缓存。纹理内存是一种通过指定的只读缓存访问的全局内存。只读缓存包括硬件滤波的支持,它可以将浮点插入作为读过程的一部分来执行。纹理内存是对二维空间局部性的优化,所以线程束里使用纹理内存访问二维数据的线程可以达到最优性能。
全局内存
全局内存是GPU中最大、延迟最高并且最常使用的内存。global指的是其作用域和生命周期。它的声明可以在任何SM设备上被访问到,并且贯穿应用程序的整个生命周期。
一个全局内存变量可以被静态声明或动态声明。可以使用__device__修饰符在设备代码中静态地声明一个变量。
在主机端使用cudaMalloc函数分配全局内存,使用cudaFree函数释放全局内存。然后指向全局内存的指针就会作为参数传递给核函数。全局内存分配空间存在于应用程序的整个生命周期中,并且可以访问所有核函数中的所有线程。
全局内存常驻于设备内存中,可通过32字节、64字节或128字节的内存事务进行访问。这些内存事务必须自然对齐。
GPU缓存
GPU缓存是不可编程的内存。在GPU上有4种缓存:


文件作用域中的变量:可见性与可访问性
一般情况下,设备核函数不能访问主机变量,并且主机函数也不能访问设备变量。即使这些变量在同一文件作用域内被声明。
CUDA运行时API能够访问主机和设备变量。
二、内存管理
1. 内存分配和释放
在主机上使用下列函数分配全局内存:
cudaError_t cudaMalloc(void **devPtr, size_t count);这个函数在设备上分配了count字节的全局内存,并用devptr指针返回该内存的地址。如果cudaMalloc函数执行失败则返回cudaErrorMemoryAllocation。在已分配的全局内存中的值不会被清除。你需要用从主机上传输的数据来填充所分配的全局内存,或用下列函数将其初始化:
cudaError_t cudaMemset(void *devPtr, int value, size_t count);这个函数用存储在变量value中的值来填充从设备内存地址devPtr处开始的count字节。
一旦一个应用程序不再使用已分配的全局内存,那么可以用以下代码释放该内存空间:
cudaError_t cudaFree(void *devPtr);这个函数释放了devPtr指向的全局内存,该内存在此前使用了一个设备分配函数(如cudaMalloc)来进行分配。否则,它将返回一个错误cudaErrorInvalidDevicePointer。如果地址空间已经被释放,那么cudaFree也返回一个错误。
设备内存的分配和释放操作成本较高,所有应用程序应重利用设备内存,以减少对整体性能的影响。
2. 内存传输
一旦分配好了全局内存,你就可以使用下列函数从主机向设备传输数据:
cudaError_t cudaMemcpy(void *dst, const void *src, size_t count, enum cudaMemcpyKind kind);这个函数从内存位置src复制了count字节到内存位置dst。变量kind指定了复制的方向,可以有下列取值:
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemcpyDeviceToDevice
如果指针dst和src与kind指定的复制方向不一致,那么cudaMemcpy的行为就是未定义行为。这个函数在大多数情况下都是同步的。
3. 固定内存
分配的主机内存默认是pageable(可分页)。当从可分页主机内存传输数据到设备内存时,CUDA驱动程序首先分配临时页面锁定的或固定的主机内存,将主机源数据复制到固定内存中,然后从固定内存传输数据给设备内存。

CUDA运行时允许你使用如下指令直接分配固定主机内存:
cudaError_t cudaMallocHost(void **devPtr, size_t count);
这个函数分配了count字节的主机内存,这些内存是页面锁定的并且对设备来说是可访问的。由于固定内存能被设备直接访问,所以它能用比可分页内存高得多的带宽进行读写。

#include <cuda_runtime.h>
#include <stdio.h>int main(int argc, char **argv)
{// set up deviceint dev = 0;CHECK(cudaSetDevice(dev));// memory sizeunsigned int isize = 1 << 22;unsigned int nbytes = isize * sizeof(float);// get device informationcudaDeviceProp deviceProp;CHECK(cudaGetDeviceProperties(&deviceProp, dev));if (!deviceProp.canMapHostMemory) // 检查设备是否支持固定内存映射{printf("Device %d does not support mapping CPU host memory!\n", dev);CHECK(cudaDeviceReset());exit(EXIT_SUCCESS);}printf("%s starting at ", argv[0]);printf("device %d: %s memory size %d nbyte %5.2fMB canMap %d\n", dev,deviceProp.name, isize, nbytes / (1024.0f * 1024.0f),deviceProp.canMapHostMemory);// allocate pinned host memoryfloat *h_a;CHECK(cudaMallocHost ((float **)&h_a, nbytes));// allocate device memoryfloat *d_a;CHECK(cudaMalloc((float **)&d_a, nbytes));// initialize host memorymemset(h_a, 0, nbytes);for (int i = 0; i < isize; i++) h_a[i] = 100.10f;// transfer data from the host to the deviceCHECK(cudaMemcpy(d_a, h_a, nbytes, cudaMemcpyHostToDevice));// transfer data from the device to the hostCHECK(cudaMemcpy(h_a, d_a, nbytes, cudaMemcpyDeviceToHost));// free memoryCHECK(cudaFree(d_a));CHECK(cudaFreeHost(h_a));// reset deviceCHECK(cudaDeviceReset());return EXIT_SUCCESS;
}
与可分页内存相比,固定内存的分配和释放成本更高,但是它为大规模数据传输提供了更高的传输吞吐量。
4. 零拷贝内存
通常来说,主机不能直接访问设备变量,同时设备也不能直接访问主机变量。但有一个例外:零拷贝内存。主机和设备都可以访问零拷贝内存。
在CUDA核函数中使用零拷贝内存有以下几个优势。

零拷贝内存是固定(不可分页)内存,该内存映射到设备地址空间中。你可以通过下列函数创建一个到固定内存的映射:
cudaError_t cudaHostAlloc(void **pHost, size_t count, unsigned int flags);这个函数分配了count字节的主机内存,该内存是页面锁定的且设备可访问的。用这个函数分配的内存必须用cudaFreeHost函数释放。flags参数可以对已分配内存的特殊属性进一步进行配置:
· cudaHostAllocDefault
` cudaHostAllocPortable
` cudaHostAllocWriteCombined
` cudaHostAllocMapped

在进行频繁的读写操作时,使用零拷贝内存作为设备内存的补充将显著降低性能。因为每一次映射到内存的传输必须经过PCIe总线。
举例:用零拷贝内存加总数组

// part 2: using zerocopy memory for array A and B// allocate zerocpy memoryCHECK(cudaHostAlloc((void **)&h_A, nBytes, cudaHostAllocMapped));CHECK(cudaHostAlloc((void **)&h_B, nBytes, cudaHostAllocMapped));// initialize data at host sideinitialData(h_A, nElem);initialData(h_B, nElem);memset(hostRef, 0, nBytes);memset(gpuRef, 0, nBytes);// pass the pointer to deviceCHECK(cudaHostGetDevicePointer((void **)&d_A, (void *)h_A, 0));CHECK(cudaHostGetDevicePointer((void **)&d_B, (void *)h_B, 0));// add at host side for result checkssumArraysOnHost(h_A, h_B, hostRef, nElem);// execute kernel with zero copy memorysumArraysZeroCopy<<<grid, block>>>(d_A, d_B, d_C, nElem);// copy kernel result back to host sideCHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));// check device resultscheckResult(hostRef, gpuRef, nElem);// free memoryCHECK(cudaFree(d_C));CHECK(cudaFreeHost(h_A));CHECK(cudaFreeHost(h_B));free(hostRef);free(gpuRef);

5. 统一虚拟寻址(UVA)
在UVA之前,你需要管理哪些指针指向主机内存和哪些指针指向设备内存。有了UVA,主机内存和设备内存可以共享同一个虚拟地址空间。
通过UVA,由cudaHostAlloc分配的固定主机内存具有相同的主机和设备指针。因此,可以将返回的指针直接传递给核函数。
有了UVA,无须获取设备指针或管理物理上数据完全相同的两个指针。UVA会进一步简化前面的sumArrayZerocpy.cu示例:

6. 统一内存寻址


使用托管内存的程序行为与使用未托管内存的程序副本行为在功能上是一致的。但是,使用托管内存的程序可以利用自动数据传输和重复指针消除功能。
三、内存访问模式
CUDA执行模型的显著特征之一就是指令必须以线程束为单位进行发布和执行。存储操作也是同样。
全局内存通过缓存来实现加载/存储。核函数的内存请求通常是在DRAM设备和片上内存间以128字节或32字节内存事务来实现的。
所有对全局内存的访问都通过二级缓存,也有许多访问会通过一级缓存,这取决于访问类型和GPUU架构。如果这两级缓存都被用到,那么内存访问是由一个128字节的内存事务实现的。如果只使用了二级缓存,那么这个内存访问是由一个32字节的内存事务实现的。

在优化应用程序时,需要注意内存访问的两个特性:
· 对齐内存访问
· 合并内存访问
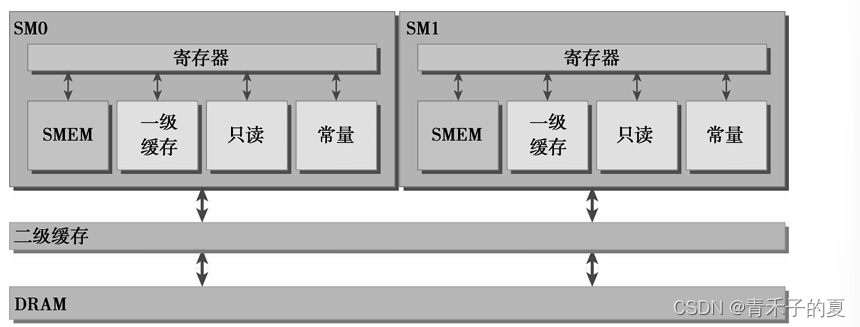
当设备内存事务的第一个地址是用于事务服务的缓存粒度的偶数倍时(32字节的二级缓存或128字节的一级缓存),就会出现对齐内存访问。运行非对齐的加载会造成带宽浪费。
当一个线程束中全部的32个线程访问一个连续的内存块时,就会出现合并内存访问。
1. 全局内存读取
在SM中,数据通过以下3种缓存/缓冲路径进行传输:
· 一级和二级缓存
· 常量缓存
· 只读缓存
一/二级缓存是默认路径。想要通过其他两种路径传递数据需要应用程序显式地说明。
全局内存加载是否会通过一级缓存取决于两个因素:设备端计算能力和编译器选项。
以下标志通知编译器禁用一级缓存:-Xptxas -dlcm=cg。如果一级缓存被禁用,所有对全局内存的加载请求将直接进入到二级缓存中,如果二级缓存缺失,则由DRAM完成请求。每一次内存事务可由一个、两个或四个部分执行,每个部分有32个字节。
一级缓存也可以使用下列标识符直接启用:-Xptxas -dlcm=ca。设置这个标志后,全局内存加载请求首先尝试通过一级缓存,如果一级缓存缺失,该请求转向二级缓存。如果二级缓存缺失,则请求由DRAM完成。在这种情况下,一个内存加载请求由一个128字节的设备内存事务实现。
内存加载访问模式

缓存加载
缓存加载操作经过一级缓存,在粒度为128字节的一级缓存行上由设备内存事务进行传输。缓存加载可以分为对齐/非对齐及合并/非合并。
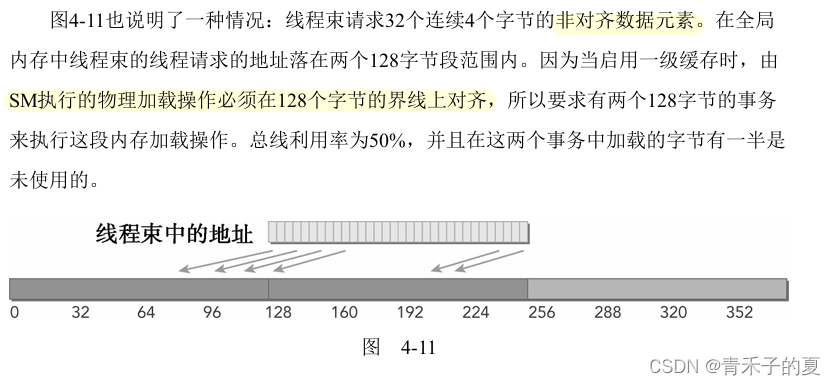
CPU一级缓存和GPU一级缓存之间的差异
CPU一级缓存优化了时间和空间局部性。GPU一级缓存是专为空间局部性而不是为时间局部性设计的。
没有缓存的加载
没有缓存的加载在内存段的粒度上(32字节)而非缓存池的粒度(128字节)执行。更细粒度的加载可以为非对齐或非合并的内存访问带来更好的总线利用率。
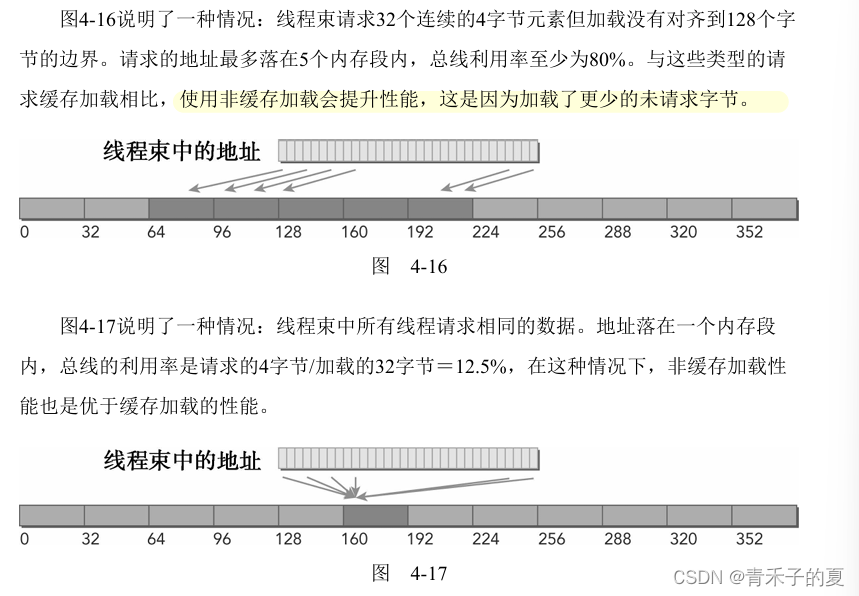
只读缓存
只读缓存的加载粒度是32个字节。通常,对分散读取来说,这些更细粒度的加载要优于一级缓存。
有两种方式可以指导内存通过只读缓存进行读取:
· 使用函数_ldg
· 在间接引用的指针上使用修饰符

2. 全局内存写入
存储操作在32个字节段的粒度上被执行。内存事务可以被分为一段、两段或四段。例如,如果两个地址同属于一个128个字节区域,但是不属于一个对齐的64个字节区域,则会执行一个四段事务(也就是说,执行一个四段事务比执行两个一段事务效果更好)。
3. 结构体数组(AoS)与数组结构体(SoA)


许多并行编程范式,尤其是SIMD型范式,更倾向于使用SoA。在CUDA C编程中也普遍倾向于使用SoA,因为数据元素是为全局内存的有效访问而预先准备好的,而被相同内存操作引用的同字段数据元素在存储时是彼此相邻的。
4. 性能调整
优化设备内存带宽利用率有两个目标:
· 对齐及合并内存访问,以减少带宽的浪费
· 足够的并发内存操作,以隐藏内存延迟
实现并发内存访问最大化是通过以下方式获得的:
· 增加每个线程中执行独立内存操作的数量(展开)
· 对核函数启动的执行配置进行实验,以充分体现每个SM的并行性
四、核函数可达到的带宽
内存延迟:完成一次独立内存请求的时间
内存带宽:SM访问设备内存的速度

1. 内存带宽
一般有如下两种类型的带宽:
· 理论带宽:当前硬件可以实现的绝对最大带宽
· 有效带宽:核函数实际达到的带宽
 (×2: 读+写)
(×2: 读+写)
2. 矩阵转置问题
假设矩阵存储在一个一维矩阵中,通过改变数组索引值来交换行和列的坐标,可以很容易得到转置矩阵。
void transposeHost(float *out, float *in, const int nx, const int ny) {for (int iy = 0; iy < ny; iy++) {for (int ix = 0; ix < nx; ix++) {out[ix * ny + iy] = in[iy * nx + ix];}}
}
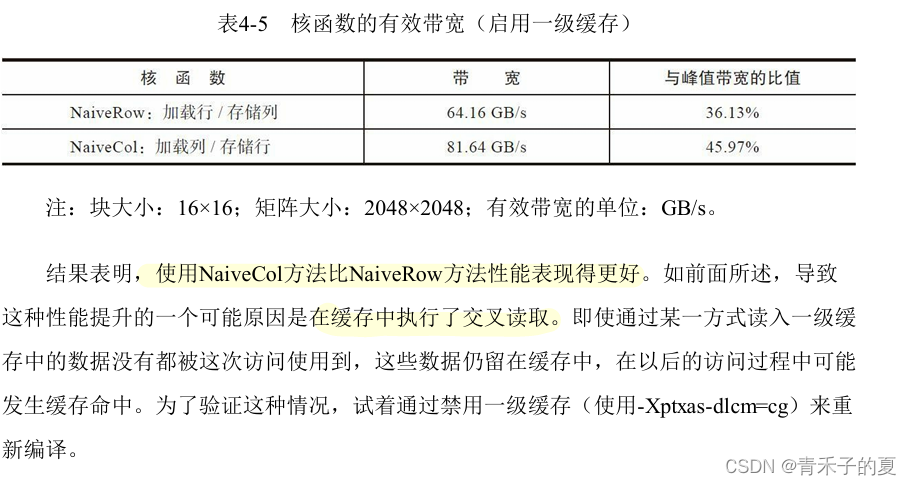
如果禁用一级缓存加载,那么两种实现的性能在理论上是相同的。但是,如果启用一级缓存,那么第二种实现的性能表现会更好。按列读取操作是不合并的(因为带宽将会浪费在未被请求的字节上),将这些额外的字节存入一级缓存意味着下一个读操作可能会在缓存上执行而不在全局内存上执行。因为写操作不在一级缓存中缓存,所以对按列执行写操作的例子而言,任何缓存都没有意义。
第一种方法:

第二种方法:

为转置核函数设置性能的上限和下限
· 通过加载和存储行来拷贝矩阵(上限)。这样将模拟执行相同数量的内存操作作为转置,这样只能使用合并访问
· 通过加载和存储列来拷贝矩阵(下限)。这样将模拟执行相同数量的内存操作作为转置,但是只能使用交叉访问
核函数的实现如下:
__global__ void copyRow(float *out, float *in, const int nx, const int ny) {unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x;unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;if (ix < nx && iy < ny) {out[iy * nx + ix] = in[iy * nx + ix];}
}__global__ void copyCol(float *out, float *in, const int nx, const int ny) {unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x;unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;if (ix < nx && iy < ny) {out[ix * ny + iy] = in[ix * ny + iy];}
}在禁用ECC的Fermi M2090上两个拷贝核函数的性能(启用一级缓存)

朴素转置:读取行与读取列
基于行的朴素转置核函数,按行加载按列存储:
__global__ void transposeNaiveRow(float *out, float *in, const int nx, const int ny) {unsigned int ix = blockIdx.x * blockDim.x + threadIdx.x;unsigned int iy = blockIdx.y * blockDim.y + threadIdx.y;if (ix < nx && iy < ny) {out[ix * ny + iy] = in[iy * nx + ix];}
}基于列的朴素转置核函数,按列加载按行存储:
__global__ void transposeNaiveCol(float *out, float *in, const int nx, const int ny) {unsigned int ix = blockDim.x * blockIdx.x + threadIdx.x;unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;if (ix < nx && iy < ny) {out[iy * nx + ix] = in[ix * ny + iy]}
}



展开转置:读取行与读取列
展开因子为4的基于行的实现:
__global__ void transposeUnroll4Row(float *out, float *in, const int nx, const int ny) {unsigned int ix = blockDim.x * blockIdx.x * 4 + threadIdx.x;unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;unsigned int ti = iy * nx + ix; // access in rowsunsigned int to = ix * ny + iy; // access in columnsif (ix + 3 * blockDim.x < nx && iy < ny) {out[to] = in[ti];out[to + ny * blockDim.x] = in[ti + blockDIm.x];out[to + ny * 2 * blockDim.x] = in[ti + 2 * blockDIm.x];out[to + ny * 3 * blockDim.x] = in[ti + 3 * blockDIm.x];}
}展开因子为4的基于列的实现:
__global__ void transposeUnroll4Col(float *out, float *in, const int nx, const int ny) {unsigned int ix = blockDim.x * blockIdx.x * 4 + threadIdx.x;unsigned int iy = blockDim.y * blockIdx.y + threadIdx.y;unsigned int ti = iy * nx + ix; // access in rowsunsigned int to = ix * ny + iy; // access in columnsif (ix + 3 * blockDim.x < nx && iy < ny) {out[ti] = in[to];out[ti + blockDim.x] = in[to + blockDIm.x * ny];out[ti + 2 * blockDim.x] = in[to + 2 * blockDIm.x * ny];out[ti + 3 * blockDim.x] = in[to + 3 * blockDIm.x * ny];}
}
对角转置:读取行与读取列





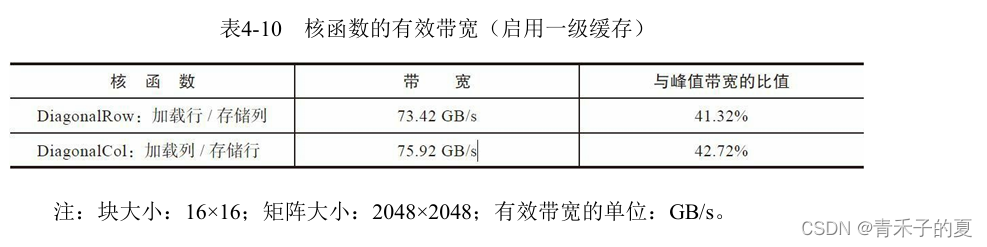

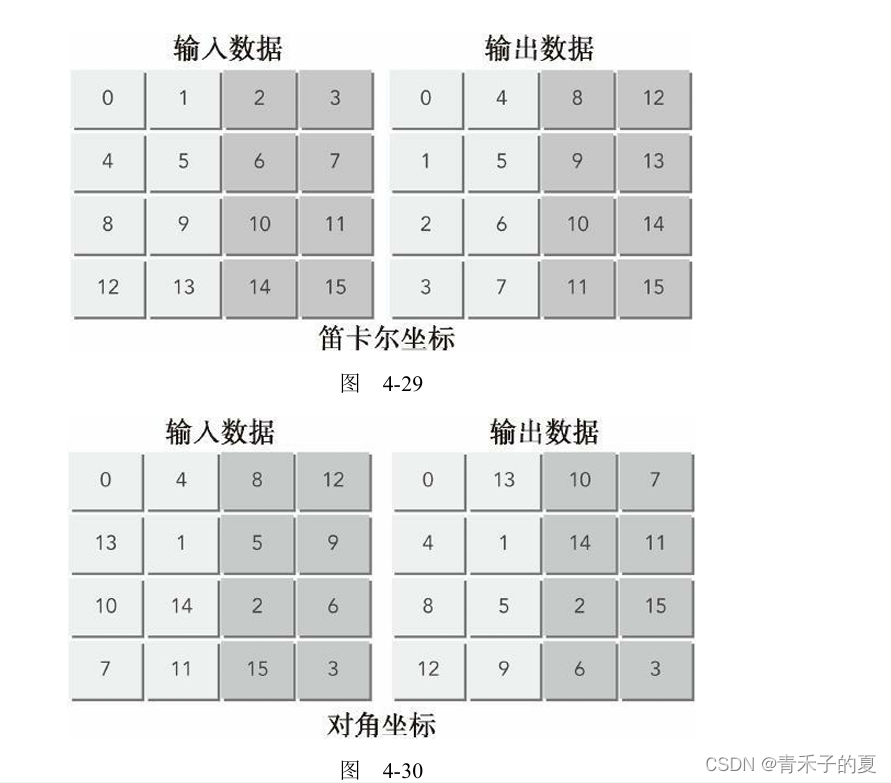 使用瘦块来增加并行性
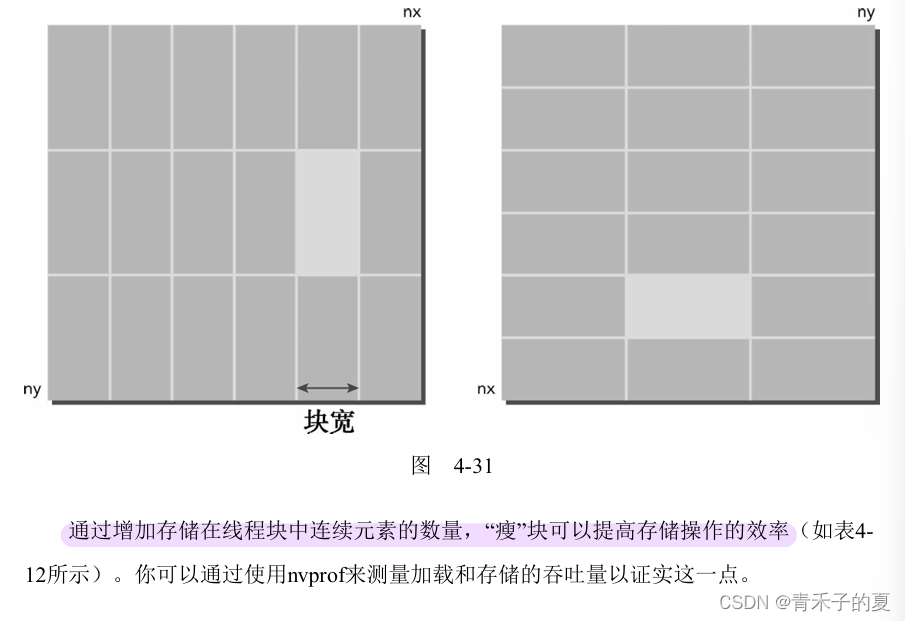
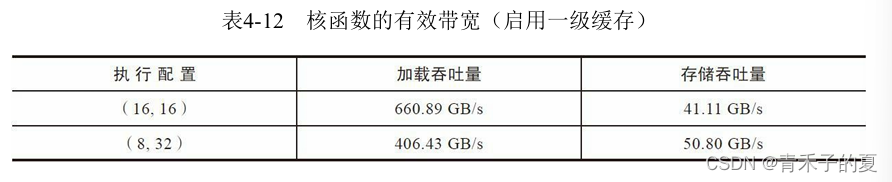
使用瘦块来增加并行性
增加并行性最简单的方式是调整块的大小。

 五、使用统一内存的矩阵加法
五、使用统一内存的矩阵加法
用托管内存分配来替换主机和设备内存分配,以消除重复指针:
 因为核函数的启动与主机程序是异步的,所以在直接访问核函数输出之前,需要在主机端显式地同步。
因为核函数的启动与主机程序是异步的,所以在直接访问核函数输出之前,需要在主机端显式地同步。
如果在一个多GPU设备的系统上进行测试,托管应用需要附加的步骤。因为托管内存分配对系统中的所有设备是可见的,所以可以限制哪一个设备对应用程序可见,这样托管内存便可以只分配在一个设备上。为此,设置环境变量CUDA_VISIBLE_DEVICES来使一个GPU对CUDA应用程序可见:
$ export CUDA_VISIBLE_DEVICES=0
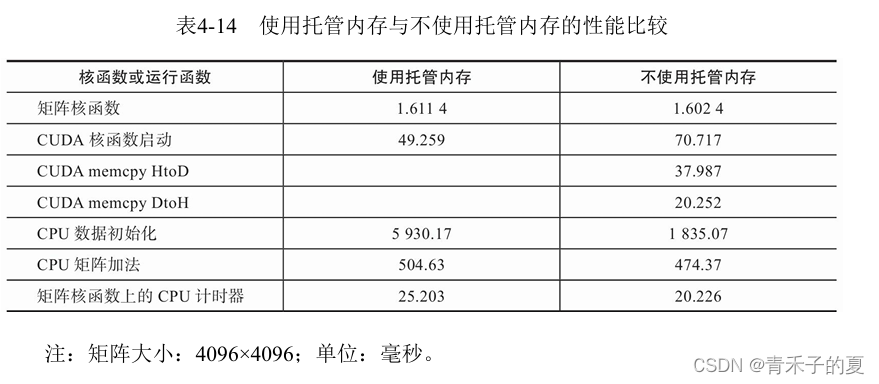
矩阵最初是在GPU上被分配的。这就要求底层系统在初始化之前,将矩阵中的数据从设备传输到主机中。故CPU数据初始化使用托管内存耗费的时间更长。
当CPU需要访问当前驻留在GPU中的托管内存时,统一内存使用CPU页面故障来触发设备到主机的数据传输。






