在人工智能快速发展的今天,企业如何选择合适的大模型应用方式成为了一个关键问题。本文将详细介绍六种主流的企业AI应用模式,帮助您根据自身需求做出最优选择。
1. 本地部署(On-Premise Deployment)
特点:将模型下载或部署在自有服务器/私有云上。
优点:
- 数据安全性高,敏感信息不出企业内网
- 可控性强,可以完全掌控模型运行环境
- 响应更快(内网通信),减少网络延迟
挑战:
- 对算力要求高,需要专业的GPU服务器
- 部署维护成本大,需要专业技术团队
实操指南:
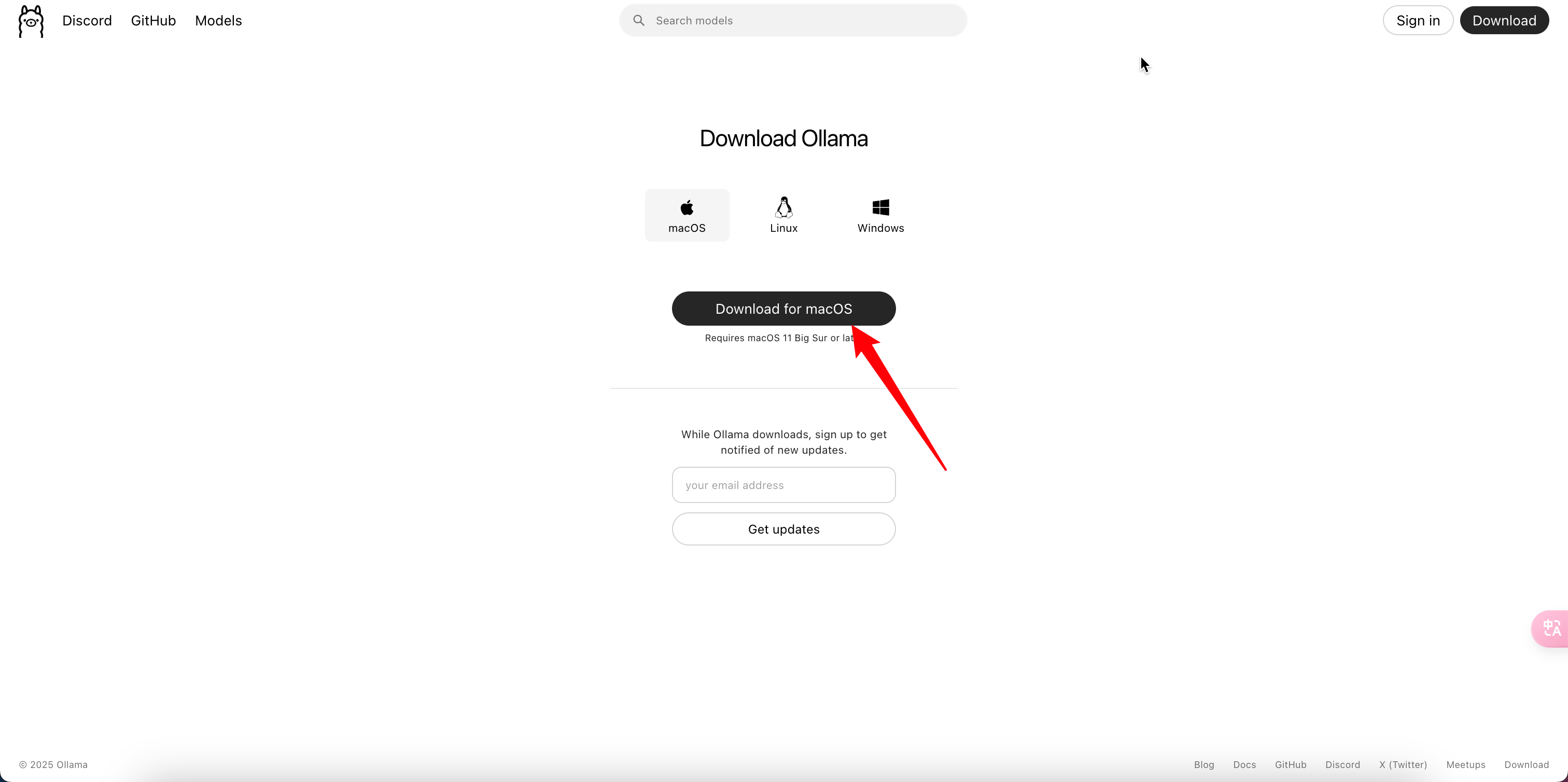
- 下载并安装Ollama(以macOS为例)
- 访问官方GitHub:https://github.com/ollama/ollama
- 下载对应系统版本安装包
- 安装AI模型
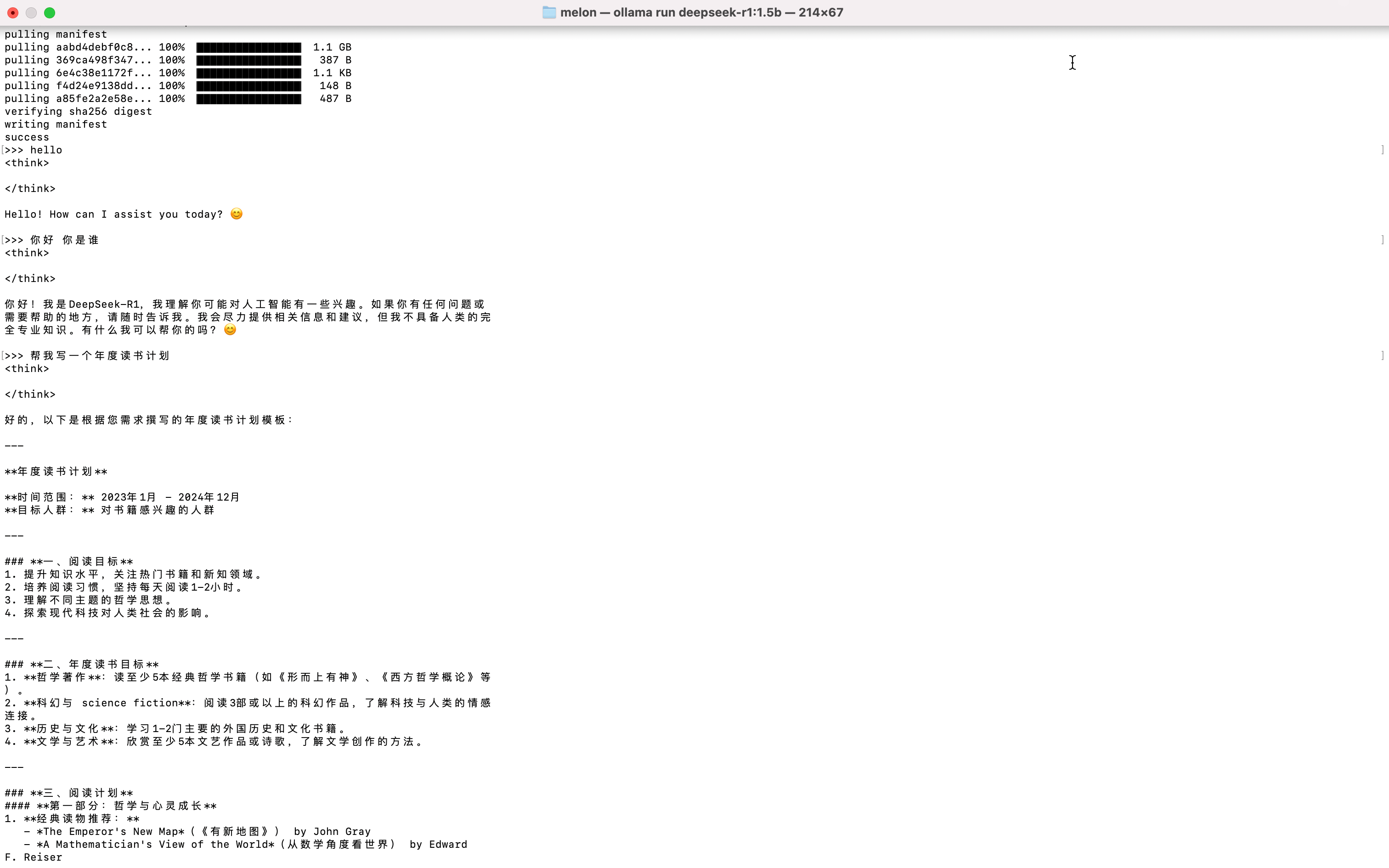
ollama run deepseek-r1:1.5b
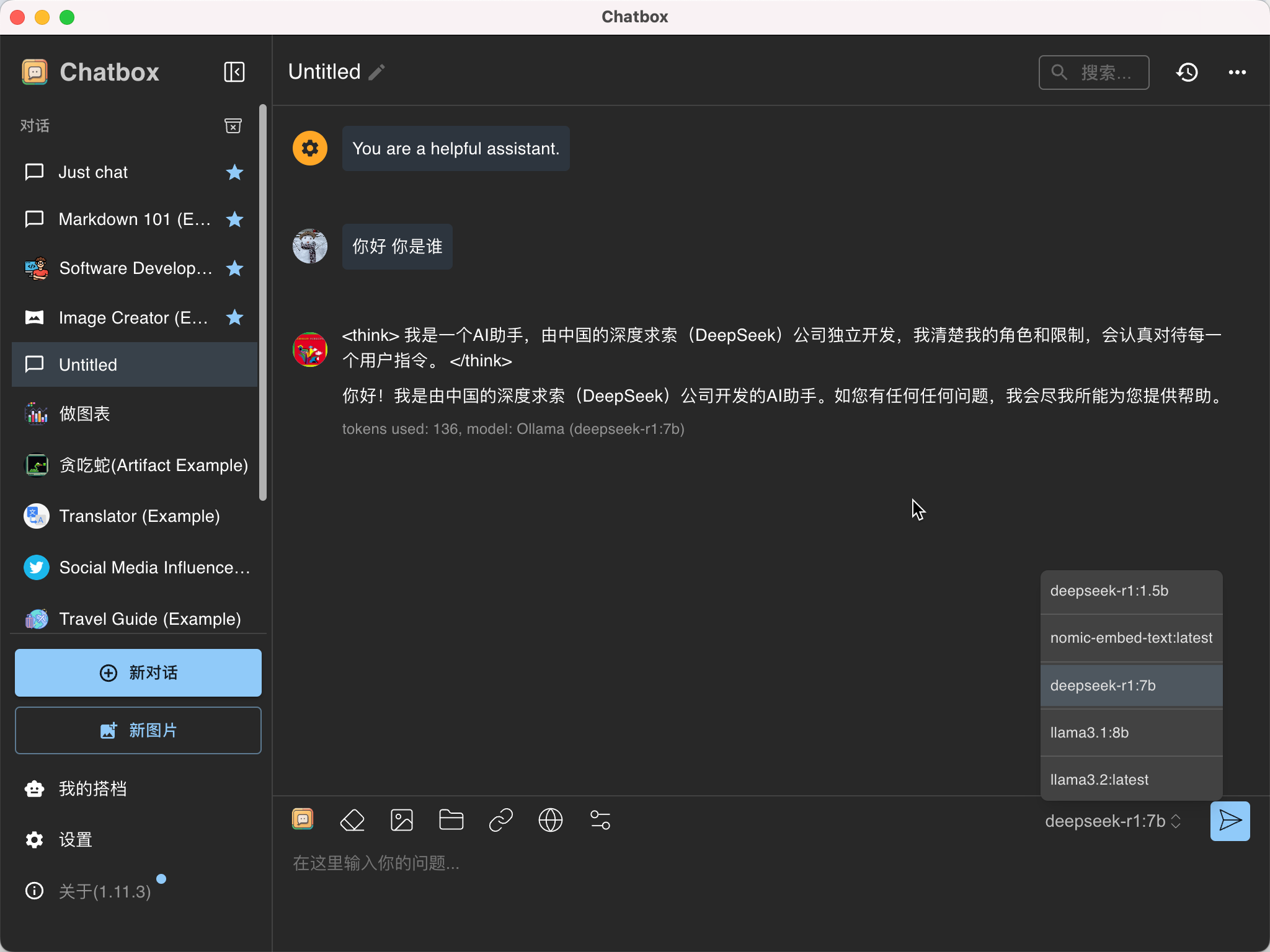
- 安装图形界面(如ChatBox)
便于日常对话使用,避免每次通过命令行交互
2. 调用第三方API(SaaS模式)
特点:通过HTTP API使用第三方模型服务(如OpenAI、百度、阿里等)。
优点:
- 零运维成本,无需关心底层模型维护
- 快速接入,开发周期短
- 模型能力强,可使用最先进的AI能力
挑战:
- 数据隐私风险,敏感信息可能泄露
- 接口使用费用持续产生
- 面临API限速或QPS限制
案例:字节跳动的飞书文档AI功能
- 智能摘要、润色、翻译等功能底层调用大模型API
- 快速上线能力强、无须自己训练维护模型
代码示例:
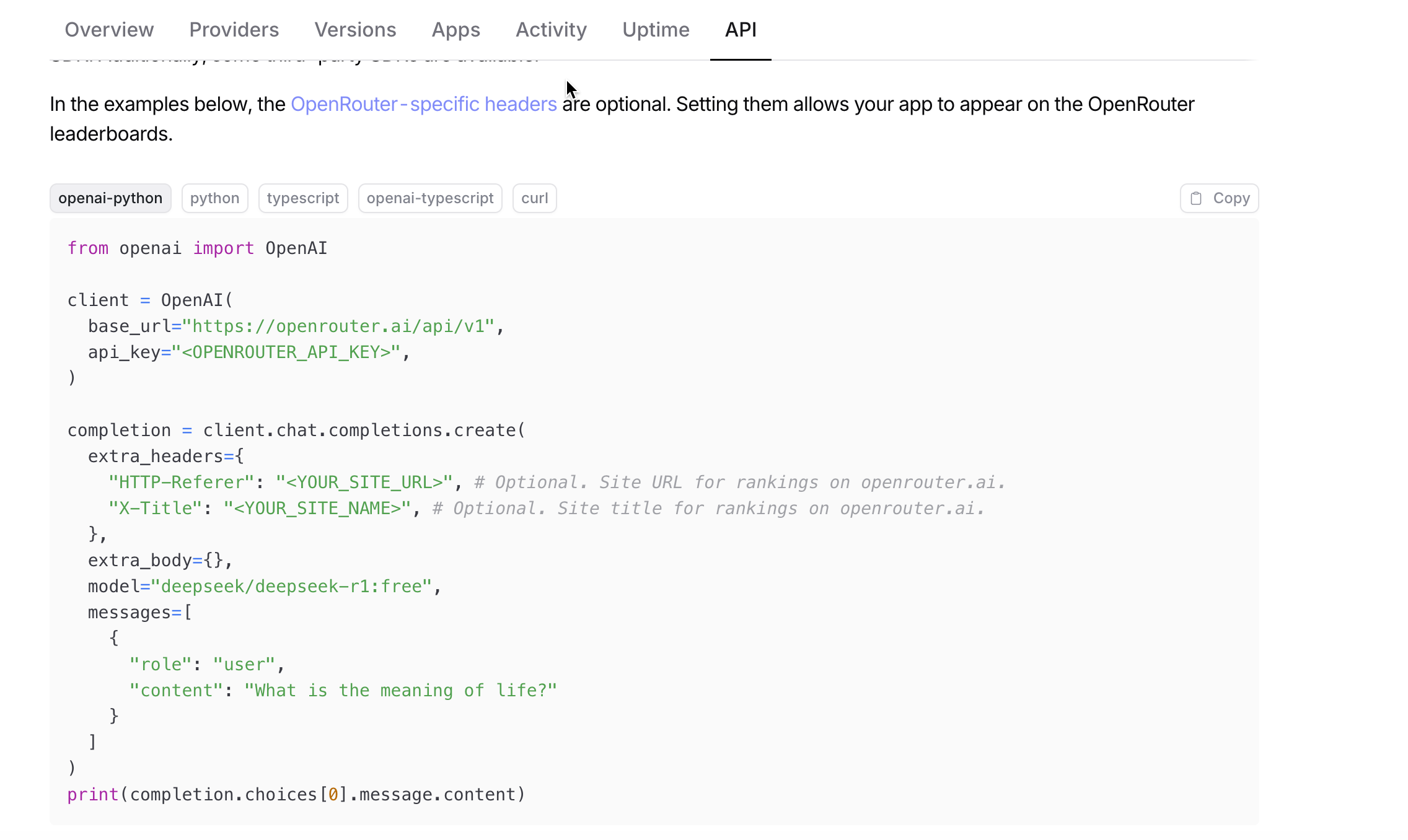
from openai import OpenAIclient = OpenAI(base_url="https://openrouter.ai/api/v1",api_key="<OPENROUTER_API_KEY>",
)completion = client.chat.completions.create(extra_headers={"HTTP-Referer": "<YOUR_SITE_URL>","X-Title": "<YOUR_SITE_NAME>",},model="deepseek/deepseek-r1:free",messages=[{"role": "user","content": "What is the meaning of life?"}]
)
print(completion.choices[0].message.content)
3. 私有云/专属大模型服务(Private Cloud)
特点:由模型服务商提供私有部署/专属实例,如阿里云"灵积专属模型服务"、华为云"盘古模型私有服务"。
优点:
- 兼顾数据安全与服务稳定性
- 可根据企业需求定制
- 减轻企业技术负担
挑战:
- 价格较高,适合大型企业
- 依赖厂商生态,有锁定风险
案例:京东云大模型服务
- 为京东零售内部提供商品文案自动生成、客服机器人等服务
- 由京东云托管部署大模型服务,内部多个BU调用
- 不需自建模型基础设施,同时保证数据安全
4. 混合部署模式(Hybrid)
特点:部分模块本地部署(如知识库、对话系统),模型推理走云端API。
优点:
- 架构灵活,可根据需求调整
- 安全性更高,敏感数据可本地处理
- 兼顾成本和性能
挑战:
- 架构设计复杂
- 需要精细化设计流量和数据处理逻辑
案例:某大型制造企业
- 内部知识库和生产线异常诊断问答系统
- 本地存储私有知识库(PDF、工单等)
- 用户提问 → 本地RAG检索 → 云端调用通义千问生成答案
- 避免私有数据出云,但享受云模型强大能力
5. 多模型调度平台(MaaS,Model-as-a-Service)
特点:如DeepSeek、字节火山、MiniMax等提供的多模型统一接入平台,支持灵活模型切换。
优点:
- 统一管理多个模型接口
- 方便进行模型对比和A/B测试
- 灵活调度不同场景下的模型使用
挑战:
- 接口封装复杂
- 依赖厂商能力
案例:腾讯混元平台
- 提供ChatGPT、混元、通义千问等多个模型选择
- 支持内部产品(如腾讯文档、企点客服等)统一调用
- 支持模型对比、流量调度、A/B测试
- 根据场景选择最适合的模型(如客服用小模型、创作用大模型)
6. 自训练/微调模型(Fine-tuning or LoRA + Inference)
特点:对开源大模型进行微调,部署后推理使用。
优点:
- 高度定制化,可适配特定业务场景
- 完全自主可控
- 针对性强,在特定领域表现更佳
挑战:
- 需要专业的模型训练经验
- 计算资源需求大
- 工程和研发成本高
案例:某医疗SaaS公司
- 训练医学对话助手,用于医生辅助问诊
- 在ChatGLM-6B基础上,微调医生-患者对话数据
- 使用QLoRA技术微调后部署在本地
- 专业性强,术语和语气高度定制化
- 难点在于需要NLP工程师、显卡资源和训练调参经验
选择建议
- 如果您的企业偏重数据安全或有严格的行业合规要求(如金融、医疗),私有化部署或私有云服务是更安全的选择
- 如果您追求快速试错、产品原型验证,API接入和混合部署提供了更高的灵活性和更低的启动成本
- 每种方式各有优劣,需要根据企业自身的技术实力、预算、安全需求和场景特点做出综合评估
无论选择哪种方式,大模型技术都将为企业带来前所未有的创新可能,关键在于找到最适合自身需求的应用模式。





