一、回归与分类问题中的损失函数选择
在机器学习中,对于不同类型的问题,我们通常需要选择合适的损失函数来指导模型的学习过程。损失函数的选择不仅影响模型的性能,还直接关系到优化过程的效率与结果的精准性。特别是在回归预测和分类问题之间,损失函数的性质和应用差异显著。以下是对均方误差(MSE)和交叉熵损失函数(Cross-Entropy Loss)的对比分析。
1.1、均方误差(MSE)在回归问题中的应用
均方误差是指预测值与实际值之间差异的平方的平均值。

-
优点: MSE能够直观反映出预测值与实际值之间的距离(L2距离),因而在回归问题中表现出色。
-
应用: 适用于连续输出变量的情况,例如房价预测、温度预测等。在这些问题中,输出值可以是任意实数,MSE能够有效度量和优化模型的预测能力。
1.2、分类问题中的损失函数
在分类任务中,我们通常会将输入样本分为不同的类别。例如,红色点的标签可以设定为0,蓝色点的标签设定为1。此时,MSE并不是一个有效的损失函数选择,原因如下:
MSE的局限性: 对于分类问题,MSE无法有效地度量不同类别之间的差异。这是因为在分类情况下,类标签是离散的,而MSE主要设计用于处理连续值构成的损失,这可能导致对类别边界优化的不敏感,进而影响分类模型的性能。
激活函数的输出: 在分类问题中,我们通常使用Sigmoid或Softmax等非线性激活函数,使得模型输出能够被解释为概率。例如,Sigmoid函数将输出范围限制在0到1之间,从而表示某一事件发生的概率。这种输出形式与分类任务的标签(通常为0或1)相一致。
1.3、交叉熵损失函数(Cross-Entropy Loss)
交叉熵损失基于信息论,衡量两个概率分布的相似性,特别是在类别预测中表现突出。

-
优点: 交叉熵能够在多分类任务中更敏感地度量预测分布与真实分布之间的距离,优化效率更高,从而提供更好的梯度信息,促使模型快速收敛。
-
应用: 交叉熵损失尤为适合于多分类问题,如图像分类、文本分类等场景,能够有效提升模型的分类性能。
对于回归任务,均方误差是一条理想的选择,因为它有效地捕捉了预测与实际之间的距离。然而,在分类任务中,由于MSE无法有效地度量类别之间的差异,交叉熵损失函数则成为更适合的选择,提供了针对分类问题的精准梯度,促进模型的优化。根据具体的任务需求,正确选择损失函数对于提升模型性能至关重要。
二、似然值
似然值(likelihood)是统计学中用于评估模型参数的一个概念。在概率论和统计学中,似然函 数是一个表示已知一些观测数据的情况下,关于统计模型参数的概率分布的函数。 似然值则是在给定参数值的情况下,观测到数据的概率。
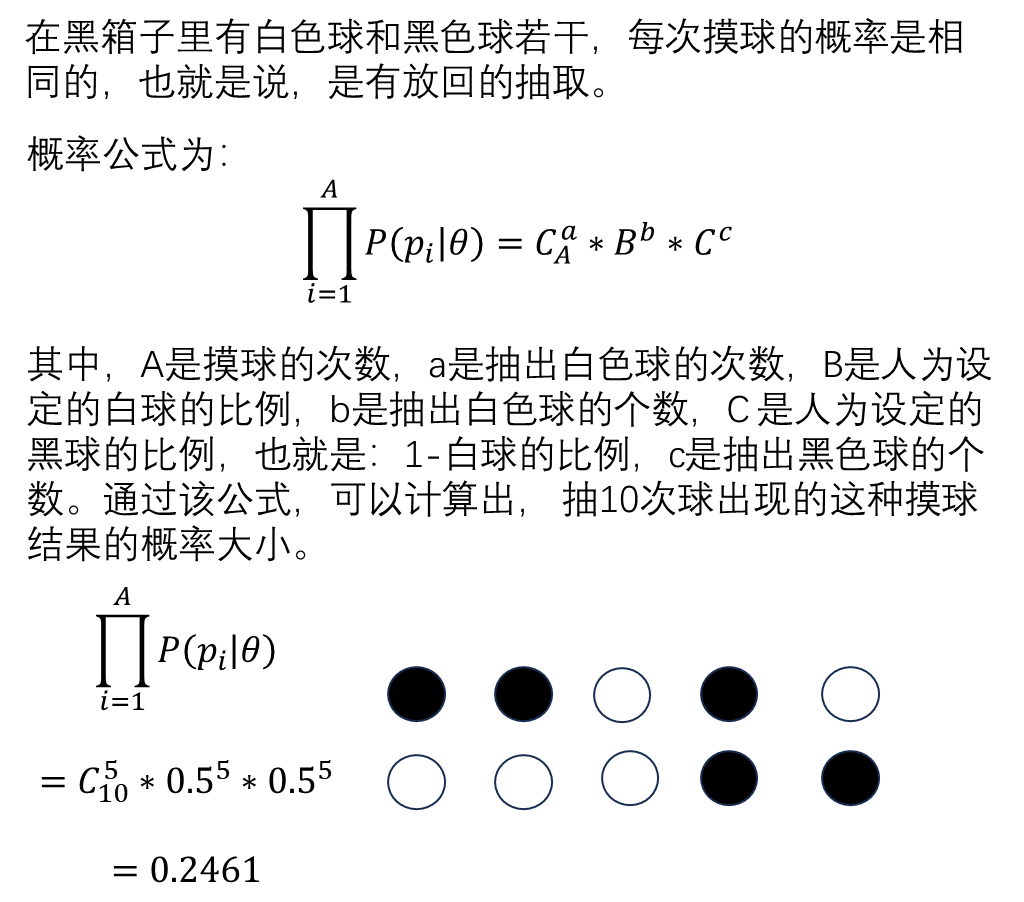
似然值是在给定参数值的情况下,观测到特定数据的概率,比如上图中抽出5个白球、5个黑球的概率是0.2461,得到的概率表示了 数据与参数值之间的匹配程度。似然值越大,说明参数值越能够解释观测到的数据,因此参数的可靠性 也越高。
三、伯努利分布
伯努利分布是描述伯努利实验结果的概率分布。具体来说,如果将“成功”定义为1,“失败”定义为 0,则伯努利分布可以用来描述在单次伯努利实验中获得特定结果(成功或失败)的概率。

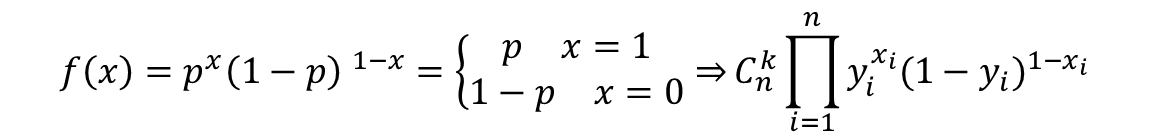
四、极大似然估计值

五、 最小化损失函数
交叉熵(Cross Entropy)是一种用于衡量两个概率分布之间差异的度量方法。在机器学习中,交叉熵常 用于衡量模型的预测结果与真实标签之间的差异。
在某些情况下(对于伯努利分布问题),极大似然估计等价于最小化交叉熵,但是极大似然估计是个递 增函数,所以将公式加上负号,成为递减函数,使用负对数似然函数来定义损失函数(通常称为交叉熵 损失函数),将最大化似然函数转化为最小化损失函数的问题。这样,在求解优化问题时,可以使用梯 度下降等优化算法来最小化负对数似然函数(或交叉熵损失函数),从而得到最大似然估计的参数 值。。
具体来说,如果假设观测数据服从某个参数化的分布,并且使用极大似然估计来估计这些参数,那么最 大化似然函数等价于最小化交叉熵。

六、代码展示
import math # 导入 math 模块,以使用数学函数 # 计算从 10 个项目中选择 0 个项目的组合数
C = math.comb(10, 0) p = 0.5 # 定义成功的概率(例如,在掷硬币时得到正面的概率) # 使用二项式概率公式计算结果:
# C * (p^k) * ((1-p)^(n-k)),其中 k = 0,n = 10
# 在这里,结果是得到 0 次成功的概率
result = C * (p ** 0) * ((1 - p) ** 10) # 注意: (1-p) 的次方是 (n-k)# 打印结果
print(result) 





)