1.Sparse vs Contiguous Adversarial Pixel Perturbations in Multimodal

标题: Models: An Empirical Analysis 多模态模型中的稀疏与连续对抗性像素扰动:实证分析
作者: Cristian-Alexandru Botocan, Raphael Meier, Ljiljana Dolamic
文章链接:https://arxiv.org/abs/2407.18251
项目代码:https://github.com/ChristianB024/SparseVsContiguityRepo

摘要:
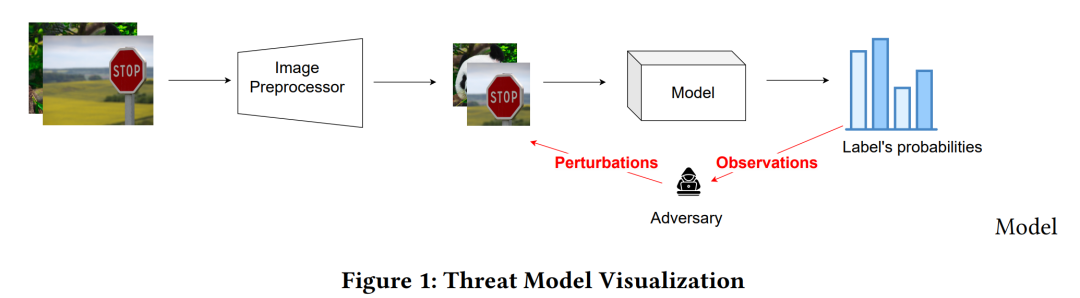
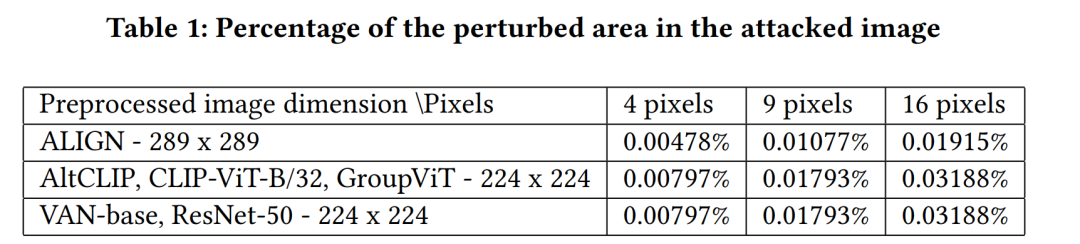
针对对抗性示例评估多模态模型的鲁棒性是确保用户安全的一个重要方面。我们对预处理的输入图像进行 L0 范数扰动攻击。我们在黑盒设置中针对四个多模态模型和两个单模态 DNN 启动它们,同时考虑了目标和非目标错误分类。我们的攻击目标是不到 0.04% 的受扰动图像区域,并集成受扰像素的不同空间定位:稀疏定位和以不同连续形状(行、列、对角线和补丁)排列的像素。据我们所知,我们是第一个评估三种最先进的多模态模型(ALIGN、AltCLIP、GroupViT)针对不同稀疏和连续像素分布扰动的鲁棒性的人。获得的结果表明单模态 DNN 比多模态模型更稳健。此外,使用基于 CNN 的图像编码器的模型比使用 ViT 的模型更容易受到攻击 - 对于非目标攻击,我们通过扰动小于 0.02% 的图像区域获得了 99% 的成功率。
这篇论文试图解决什么问题?
这篇论文主要关注于评估多模态模型(multimodal models)在对抗性示例(adversarial examples)面前的鲁棒性(robustness)。具体来说,它试图解决以下问题:
-
多模态模型对像素级扰动的脆弱性:尽管已有研究表明多模态模型对整体图像扰动是脆弱的,但对像素级别扰动的脆弱性尚未充分探索。
-
像素扰动数量和空间分布的影响:论文试图探索扰动像素的数量和它们在图像中的空间分布对攻击性能的具体影响。
-
不同类型的像素分布扰动的比较:研究者们首次评估了三种最先进的多模态模型(ALIGN, AltCLIP, GroupViT)对不同稀疏(sparse)和连续(contiguous)像素分布扰动的鲁棒性。
-
黑盒设置下的攻击:研究者们在黑盒(black-box)设置下发起攻击,模拟了攻击者没有关于模型的先验信息的情况。
-
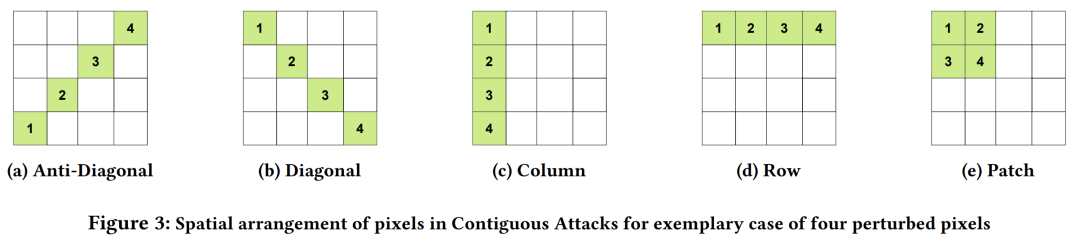
基于𝐿0-范数的扰动攻击:通过控制被扰动像素的数量,研究者们扩展了稀疏像素分布攻击,以纳入不同的空间编码,形成了五种不同的连续攻击(Contiguous Attacks)。
-
多模态与单模态模型的鲁棒性比较:通过实验分析,论文还比较了多模态模型与单模态深度神经网络(DNNs)的鲁棒性,以了解它们在面对像素扰动攻击时的差异。
总的来说,这项研究的目的是通过对多模态模型的鲁棒性进行深入的实证分析,为设计更安全的人工智能系统提供见解和指导。
论文如何解决这个问题?
论文通过以下步骤解决多模态模型在对抗性示例面前的鲁棒性问题:
-
𝐿0-范数扰动攻击:研究者们设计了基于𝐿0-范数的扰动攻击,这种攻击通过改变输入图像中特定像素的值来实现。这种方法允许研究者精确控制被扰动的像素数量。
-
黑盒设置:在黑盒设置下进行攻击,这意味着攻击者没有模型的内部信息,只能通过模型的输入和输出来进行攻击。这模拟了真实世界中攻击者可能面临的情境。
-
多模态和单模态模型的评估:研究者们对四种多模态模型(ALIGN、AltCLIP、CLIP-B/32、GroupViT)和两种单模态深度神经网络(DNNs,如ResNet-50和VAN-base)进行了评估。
-
稀疏和连续攻击:研究者们扩展了稀疏像素分布攻击,并引入了连续攻击,包括不同空间位置的像素排列(行、列、对角线、块)。
-
预处理图像的扰动:为了确保实验结果的一致性,研究者们选择在预处理后的图像上进行像素扰动,而不是原始图像。这可以消除不同预处理流程对实验结果的影响。
-
进化算法(差分进化,DE):使用差分进化算法来优化攻击,通过迭代生成更好的扰动向量。这包括突变、交叉和适应度函数的计算。
-
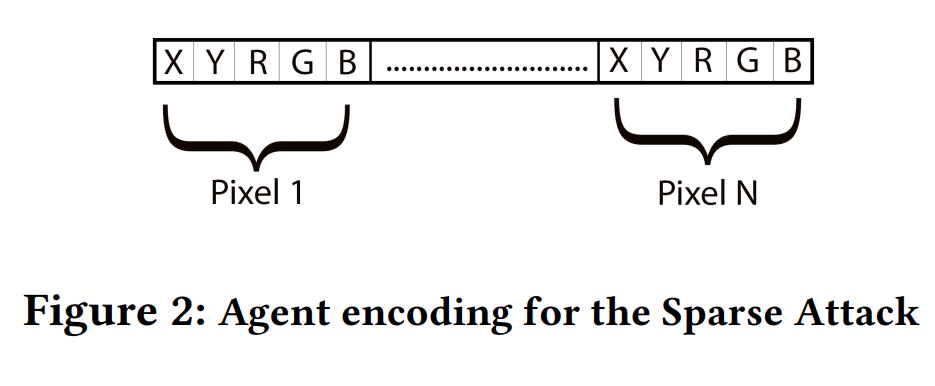
攻击编码:为稀疏攻击和连续攻击设计了不同的编码模式,以便于遗传算法的处理。
-
初始化和进化过程:在初始化过程中,为每个像素的坐标和RGB值分配随机值。在进化过程中,通过突变和交叉操作生成新的候选扰动,并通过模型查询来计算适应度值。
-
成功率(SR)评估:通过计算成功率(SR)来量化攻击的性能,即攻击成功导致误分类的图像比例。
-
实验和结果分析:在ImageNet数据集的图像上进行实验,使用不同的模型和攻击参数,然后分析结果,以了解不同模型对不同类型攻击的鲁棒性。
通过这些步骤,论文提供了对多模态模型在面对像素级扰动时的鲁棒性的深入理解,并揭示了不同模型架构对攻击的敏感性。
论文做了哪些实验?
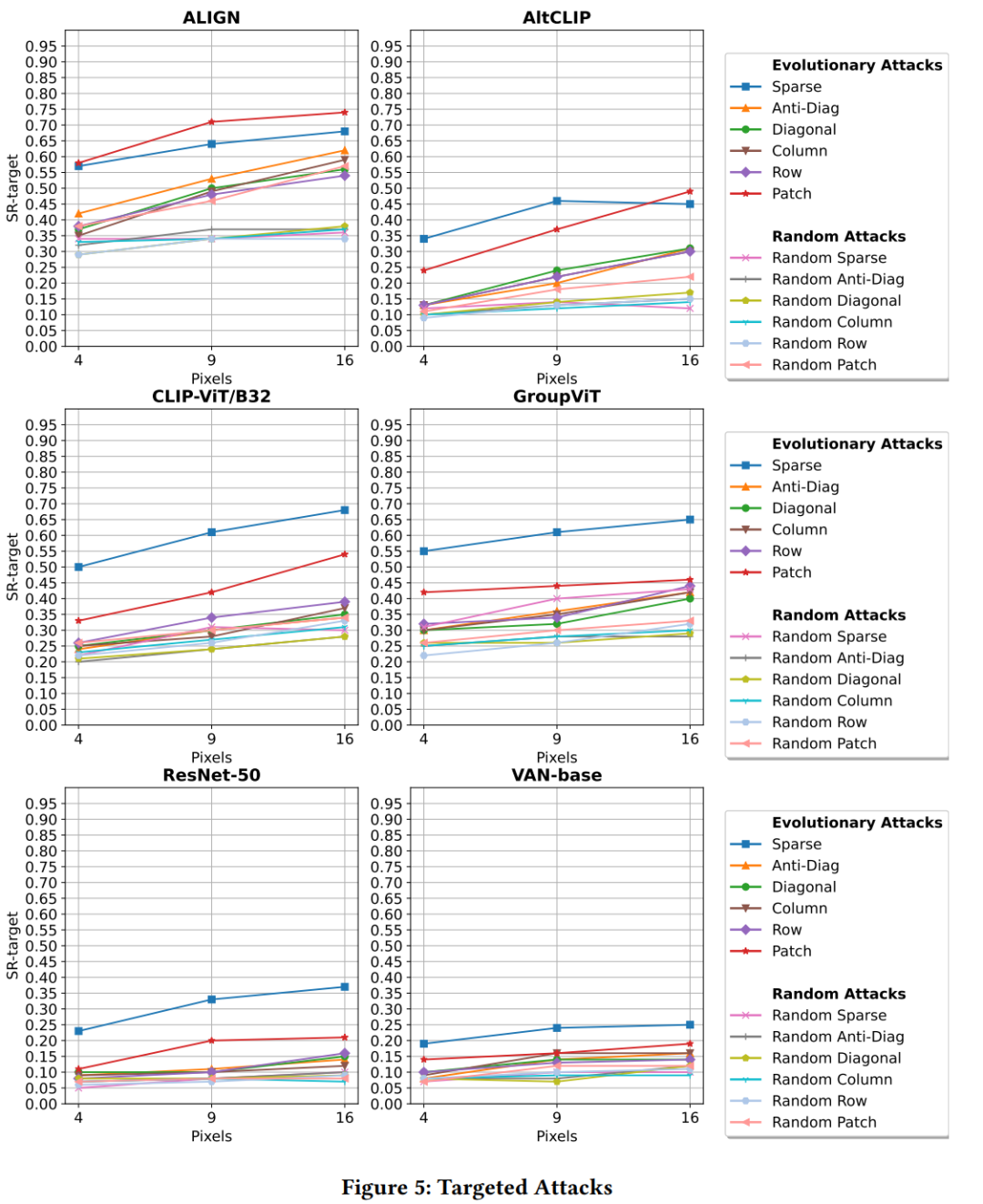
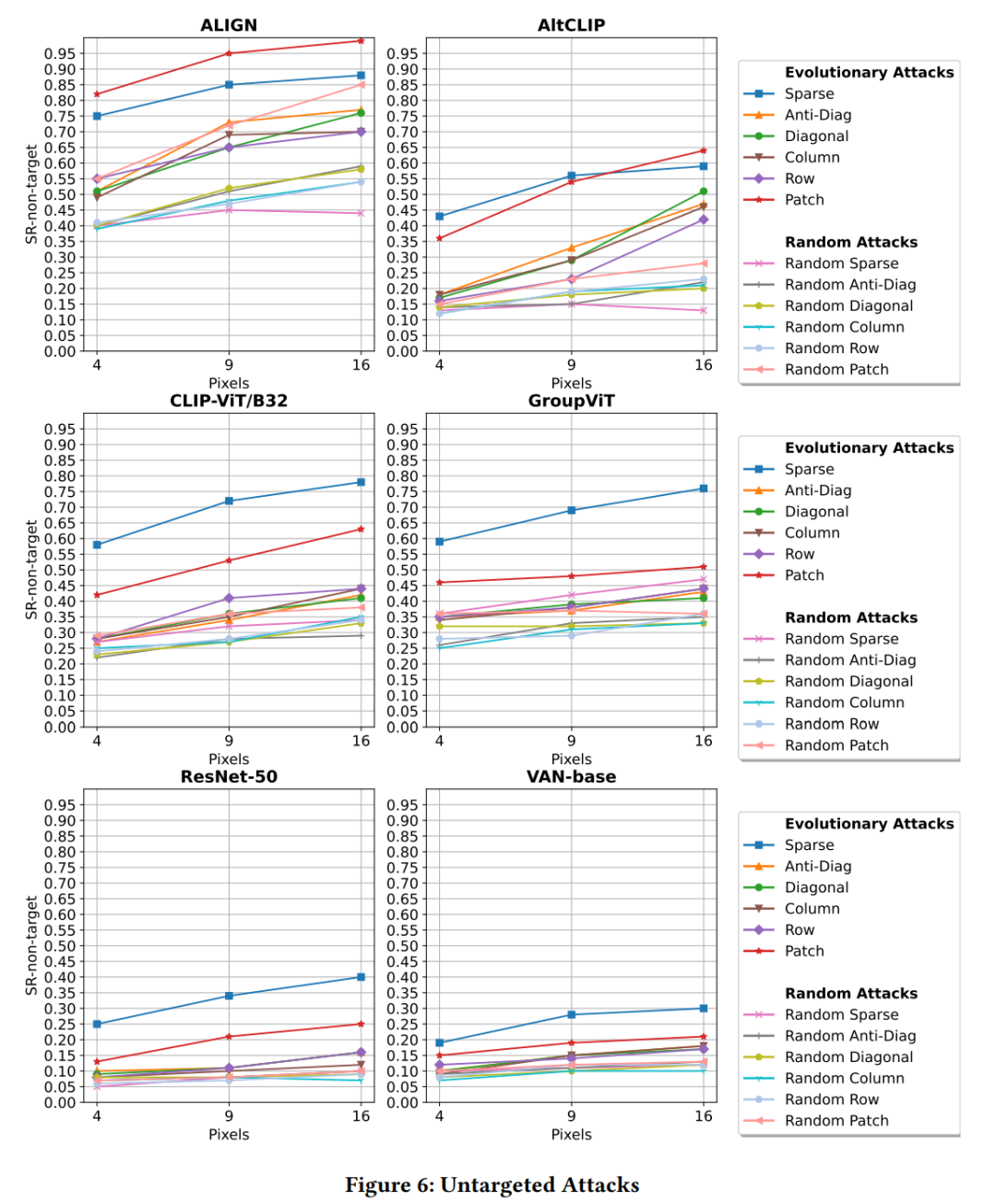
论文中进行了一系列实验来评估多模态模型和单模态深度神经网络(DNNs)在面对稀疏(Sparse)和连续(Contiguous)对抗性像素扰动时的鲁棒性。以下是实验的主要步骤和设置:
-
数据集和模型选择:实验使用了ImageNet数据集中的图像样本,并选取了四种多模态模型(ALIGN、AltCLIP、CLIP-B/32、GroupViT)和两种单模态DNNs(ResNet-50和VAN-base)作为评估对象。
-
预处理:将ImageNet数据集中的原始图像缩放到统一的分辨率(256×256),以便于进行攻击。
-
攻击类型:实验包括了稀疏攻击和连续攻击,其中连续攻击又包括了对角线、列、行和块(Anti-Diagonal、Diagonal、Column、Row、Patch)等不同的空间排列方式。
-
差分进化(DE)参数设置:为差分进化算法设置了特定的参数,包括种群大小(P=300)、迭代次数(G=100)以及突变和交叉的策略。
-
适应度函数:定义了针对目标攻击(targeted attacks)和非目标攻击(untargeted attacks)的适应度函数,使用铰链损失(hinge loss)函数来评估攻击的有效性。
-
攻击执行:通过差分进化算法生成扰动,并对每个模型进行攻击,记录每次攻击的成功与否。
-
成功率(SR)计算:通过计算成功率来量化攻击的性能,即攻击成功导致模型误分类的图像比例。
-
基线比较:为了评估进化攻击的有效性,实验还包括了随机攻击(Random Attacks)作为基线,与进化攻击的结果进行比较。
-
结果分析:对实验结果进行了详细的分析,探讨了不同类型的攻击对不同模型的影响,并讨论了可能的原因。
-
鲁棒性排名:根据SR值对模型的鲁棒性进行了排名,讨论了模型架构特性与鲁棒性之间的关系。
这些实验提供了对多模态和单模态模型在面对像素级对抗性攻击时鲁棒性的深入理解,并揭示了不同模型架构对攻击的敏感性。
论文的主要内容:
这篇论文的主要内容可以总结如下:
-
研究背景:论文强调了评估多模态模型在对抗性示例面前的鲁棒性对于保障用户安全的重要性。多模态模型结合了不同模态的信息,如文本、图像和音频,在多种应用中变得越来越重要。
-
研究目标:论文的主要目标是探索多模态模型对于像素级扰动的脆弱性,特别是考虑了扰动像素的数量和空间分布对攻击成功率的影响。
-
攻击方法:研究者们开发了基于𝐿0-范数的扰动攻击,包括稀疏(Sparse)和连续(Contiguous)两种类型的攻击。连续攻击进一步细分为行、列、对角线和块等不同的空间排列。
-
实验设置:实验在黑盒环境下进行,使用了四种多模态模型和两种单模态DNNs,针对ImageNet数据集上的图像进行了评估。
-
差分进化算法:使用差分进化算法来优化攻击,通过迭代过程生成更好的扰动向量。
-
实验结果:实验结果显示,单模态DNNs通常比多模态模型更鲁棒。在多模态模型中,使用CNN作为图像编码器的模型(如ALIGN)对连续攻击更敏感,而使用ViT的模型对稀疏攻击更敏感。
-
关键发现:
-
对于多模态模型,稀疏攻击通常更有效。
-
对于CNN基的多模态模型,如ALIGN,补丁攻击(Patch Attack)特别有效。
-
通过扰动极小部分图像区域(小于0.02%),可以实现高达99%的攻击成功率。
-
-
结论与未来工作:论文指出,多模态模型的灵活性可能以牺牲鲁棒性为代价。未来的工作将探索其他类型的多模态模型,并对连续攻击进行更深入的研究。
-
代码开源:为了促进研究的可重复性,作者还发布了实验的代码。
整体而言,这篇论文提供了对多模态模型在面对像素级对抗性攻击时鲁棒性的深入分析,并揭示了不同模型架构对攻击的敏感性差异。
2.Trajectory-aligned Space-time Tokens for Few-shot Action Recognition

标题: 用于少镜头动作识别的轨迹对齐时空标记
作者:Pulkit Kumar, Namitha Padmanabhan, Luke Luo, Sai Saketh Rambhatla, Abhinav Shrivastava
文章链接:https://arxiv.org/abs/2407.18249
项目代码:https://www.cs.umd.edu/~pulkit/tats/
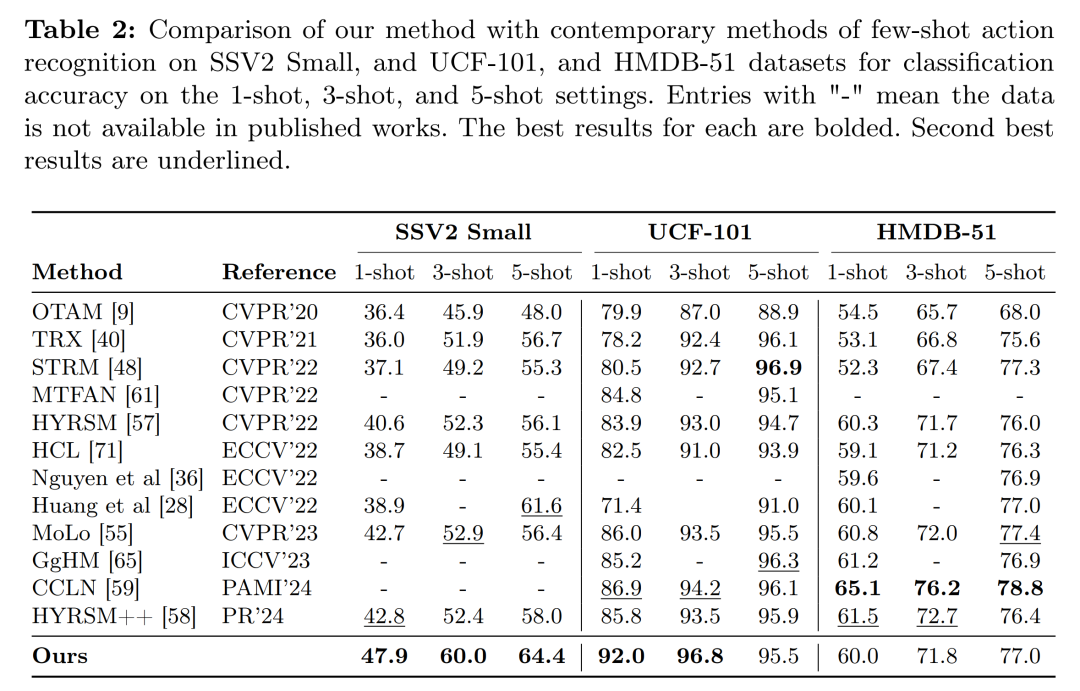
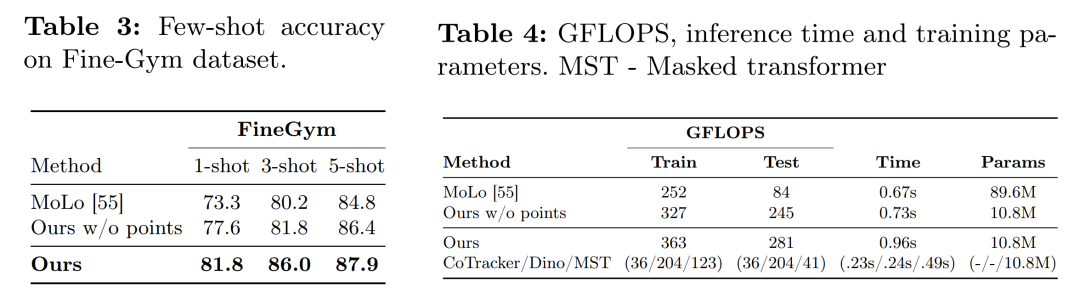
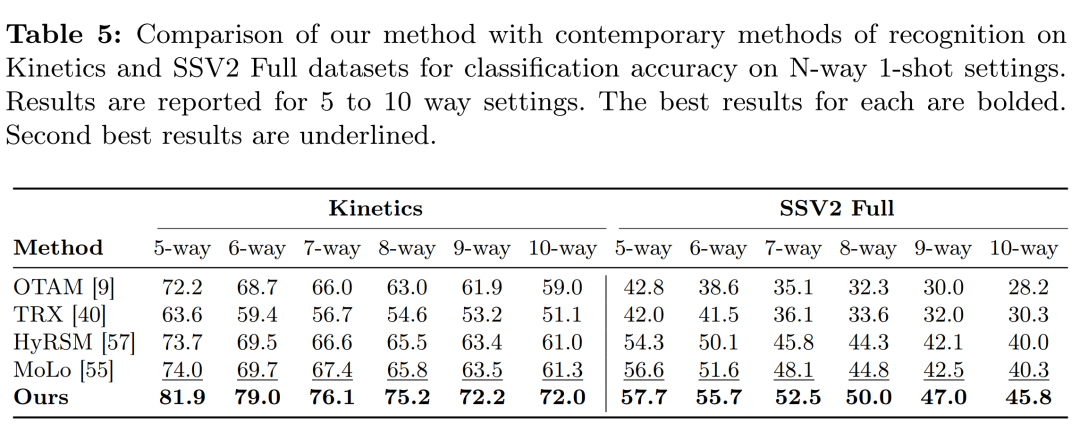
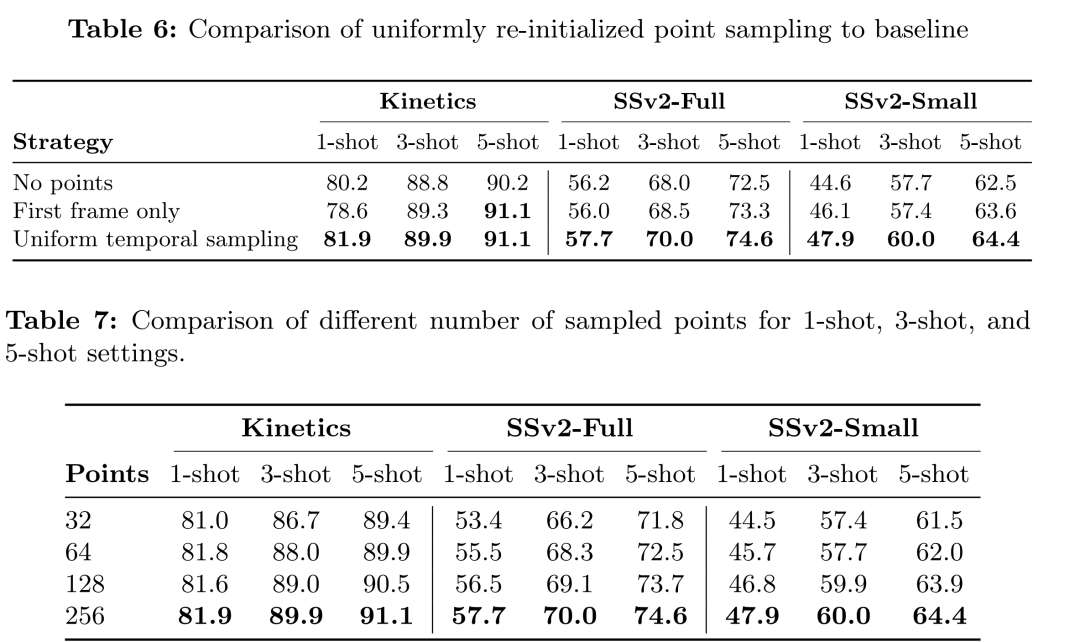


摘要:
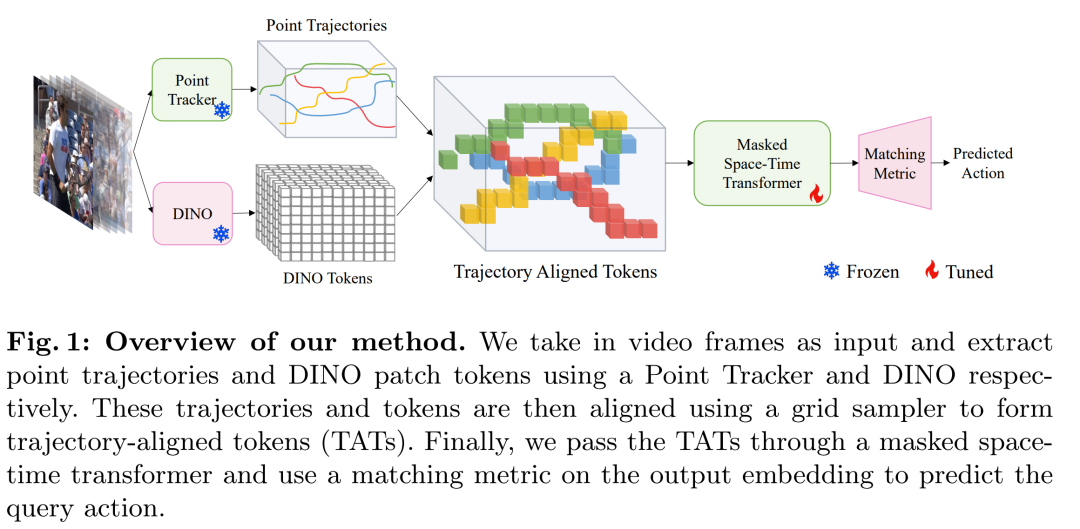
我们提出了一种简单而有效的小镜头动作识别方法,强调运动和外观表示的解开。通过利用跟踪方面的最新进展,特别是点轨迹和自监督表示学习,我们构建了捕获运动和外观信息的轨迹对齐标记(TAT)。这种方法显着减少了数据需求,同时保留了重要信息。为了处理这些表示,我们使用了一个 Masked Space-time Transformer,它可以有效地学习聚合信息以促进少镜头动作识别。我们展示了跨多个数据集的少镜头动作识别的最先进结果。
这篇论文试图解决什么问题?
: 这篇论文提出了一种针对少样本(few-shot)动作识别的方法,主要解决的问题是如何在仅有少量标注样本的情况下,有效地识别视频中的动作。具体来说,论文强调了以下几个关键点:
-
少样本学习需求:在传统的大规模训练范式中,模型通常使用大量的训练样本来学习动作的表示。然而,在少样本设置中,模型需要在只有非常有限的标注样本的情况下进行训练和识别,这要求模型能够更加精细地理解动作的构成。
-
动作的细微线索:动作识别需要识别运动和外观中的微妙线索,这些线索通常只涉及几个像素。在少样本情况下,这些信息很难通过深度网络隐式学习得到。
-
运动与外观的解耦:论文提出的方法试图将运动和外观表示解耦,以便更有效地捕捉动作的特征。这包括利用点轨迹来建模运动,然后与外观表示对齐,以适应少样本训练范式。
-
数据需求与信息保留:通过选择有限但相关的信息子集,该方法显著减少了数据需求,同时保留了关键信息。
-
自监督学习:论文利用了自监督学习方法(如DINOv2)来提取一般化的视觉特征,这些特征能够鲁棒且高效地捕捉动作引入的变化。
-
轨迹对齐的时空表示:通过轨迹对齐的表示(TATs),结合了运动和外观信息,并通过掩蔽时空变换器(Masked Space-time Transformer)来聚合信息,以促进少样本动作识别。
总的来说,这篇论文试图解决的是在少样本情况下如何有效地进行动作识别的问题,通过运动和外观的解耦以及自监督学习,提高了模型在少样本学习设置下的性能。
论文如何解决这个问题?
论文通过提出一种新颖的方法来解决少样本动作识别问题,具体解决方案包括以下几个关键步骤:
-
点轨迹跟踪:利用点跟踪技术来捕捉视频中的运动信息。通过跟踪视频中的一组点,可以获取它们在时间序列上的运动轨迹,这些轨迹能够提供关于动作的动态信息。
-
轨迹对齐的表示(TATs):将点轨迹与自监督学习得到的外观特征相结合。使用DINOv2模型提取的图像特征作为每个点的语义描述符,并将这些特征与点的轨迹对齐,形成轨迹对齐的令牌(Trajectory Aligned Tokens, TATs)。
-
掩蔽时空变换器(Masked Space-Time Transformer):设计了一种特殊的变换器架构,用于处理TATs。这个变换器使用时空注意力机制来聚合每个点的轨迹信息,并建立不同点之间的关系。
-
集合匹配度量和损失函数:使用双向均值豪斯多夫度量(Bi-MHM)作为匹配度量,结合交叉熵损失和对比损失来训练模型,以便在支持集和查询集之间进行有效的分类。
-
冻结预训练模型:在训练过程中,点跟踪器和DINOv2模型的权重被冻结,只有时空变换器接受训练。这减少了训练参数的数量,提高了训练效率。
-
实验验证:在多个数据集上进行实验,包括Something-Something、Kinetics、UCF101和HMDB51等,验证了所提方法的有效性。
通过这些步骤,论文的方法能够在少样本的情况下有效地识别视频中的动作,同时减少了对数据的需求并保留了关键信息。这种方法在多个数据集上都取得了优于现有技术的性能。
论文做了哪些实验?
论文中进行了一系列实验来验证所提出方法的有效性。以下是实验的主要部分:
-
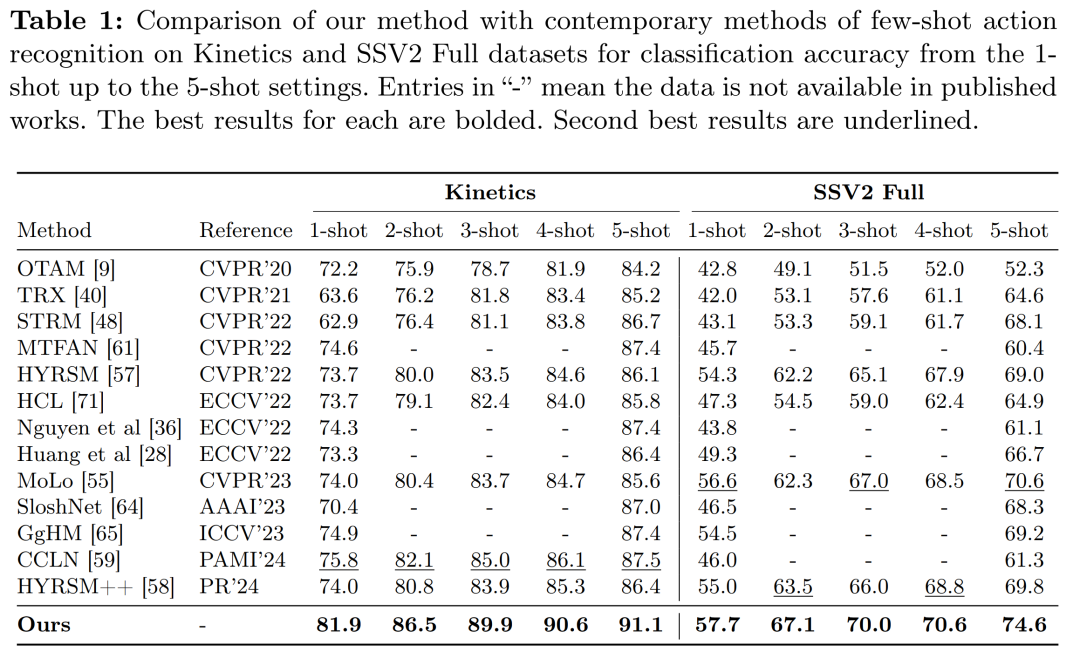
实验配置:在Something-Something、Kinetics、UCF101和HMDB51等数据集上进行了少样本动作识别的实验,采用了与先前工作相同的数据分割以保证公平比较。
-
与现有方法的比较:在5-way K-shot设置下,将提出的方法与多个现有的最先进方法进行了比较,包括OTAM、TRX、STRM、MTFAN、HYRSM、HCL、Nguyen等人的方法和Huang等人的方法等。
-
不同输入帧数的性能评估:研究了输入帧数对模型性能的影响,并发现随着输入帧数的增加,提出的方法能够利用更丰富的轨迹信息,从而提高性能。
-
计算分析:比较了模型的GFLOPS、推理时间和可训练参数与MoLo方法的情况。
-
不同N-way设置的性能:在Kinetics和SSv2 Full数据集上,对N-way 1-shot设置进行了实验,其中N的范围从5到10。
-
消融研究:通过一系列消融实验,研究了方法中不同组件的影响,包括没有使用点信息的基线、仅在第一帧初始化点、不同数量的采样点以及不同网格大小的点采样。
-
定性结果:展示了一些定性结果,其中提出的方法在某些动作识别任务上优于基线方法,特别是那些在视频中能够清晰跟踪点的动作。
-
限制讨论:讨论了方法的局限性,包括对相机运动的敏感性、处理突然场景切换视频的挑战,以及在动作识别中运动信息帮助有限的情况。
-
未来工作和讨论:提出了未来可能的研究方向,包括利用TATs解决其他视频相关任务,以及改进点采样策略等。
这些实验结果表明,提出的方法在多个数据集上都取得了优于现有技术的性能,并且在不同的实验设置下展现出了良好的鲁棒性和适应性。
论文的主要内容:
这篇论文提出了一种针对少样本动作识别的高效方法,主要内容包括:
-
问题背景:在少样本学习场景下,如何有效地从有限的标注样本中学习并识别视频中的动作是一个挑战。
-
方法概述:论文提出了一种基于轨迹对齐的时空令牌(Trajectory Aligned Tokens, TATs)的方法,通过分离运动和外观表示来增强模型对动作的识别能力。
-
关键技术:
-
利用点轨迹跟踪技术捕捉视频中的运动信息。
-
结合自监督学习(特别是DINOv2模型)提取的外观特征与点轨迹对齐,形成TATs。
-
使用掩蔽时空变换器(Masked Space-Time Transformer)处理TATs,并聚合信息。
-
-
实验验证:在多个数据集上进行实验,展示了该方法在少样本动作识别上的有效性,并与现有技术进行了比较。
-
消融研究:通过一系列消融实验,分析了不同组件对最终性能的影响,包括点采样策略、点跟踪器的选择等。
-
计算效率:论文还讨论了模型的计算效率,包括GFLOPS、推理时间和训练参数数量的比较。
-
局限性和未来工作:论文指出了方法的一些局限性,如对相机运动的敏感性,以及在动作识别中运动信息帮助有限的情况,并提出了未来可能的研究方向。
-
结论:论文总结了研究成果,认为提出的方法在少样本动作识别领域是一个重要的进步,并为未来的研究和实际应用提供了一个有力的工具。
整体上,这篇论文为少样本动作识别问题提供了一种新颖的解决方案,通过结合点轨迹跟踪和自监督学习,有效地提高了识别精度,并减少了对大量标注数据的依赖。
3.VGGHeads: A Large-Scale Synthetic Dataset for 3D Human Heads

标题: VGGHeads:3D 人体头部的大规模合成数据集
作者:Orest Kupyn, Eugene Khvedchenia, Christian Rupprecht
文章链接:https://arxiv.org/abs/2407.18245
项目代码:https://github.com/KupynOrest/head_detector




摘要:
人体头部检测、关键点估计和 3D 头部模型拟合是许多应用中的重要任务。然而,传统的现实世界数据集往往存在偏见、隐私和道德问题,而且它们是在实验室环境中记录的,这使得训练有素的模型很难推广。在这里,我们介绍 VGGHeads——一个使用扩散模型生成的大规模合成数据集,用于人体头部检测和 3D 网格估计。我们的数据集包含超过 100 万张高分辨率图像,每张图像都带有详细的 3D 头部网格、面部标志和边界框注释。使用该数据集,我们引入了一种新的模型架构,能够通过单个步骤同时从单个图像进行头部检测和头部网格重建。通过广泛的实验评估,我们证明了根据我们的合成数据训练的模型在真实图像上实现了强大的性能。此外,我们的数据集的多功能性使其适用于广泛的任务,提供人类头部的一般和全面的表示。此外,我们还提供有关合成数据生成管道的详细信息,使其能够重新用于其他任务和领域。
这篇论文试图解决什么问题?
这篇论文试图解决的主要问题是在3D人头检测、关键点估计和3D头部模型拟合等任务中,现有真实世界数据集存在的偏差、隐私和伦理问题。这些数据集通常是在实验室环境中记录的,导致训练出的模型难以泛化到现实世界的应用场景。具体来说,论文中提到的问题包括:
-
真实世界数据集的偏差问题:传统数据集可能过于关注特定方面(如面部标记),或者提供的分辨率和注释类型有限。
-
隐私和伦理问题:真实世界的数据集可能涉及隐私、伦理和同意方面的重大挑战,这使得数据的收集和使用变得困难,且可能涉及法律和伦理问题。
-
泛化能力不足:现有的基于边界框的方法通常在有限的姿态范围内运作,未能捕捉到进行准确3D建模所需的头部方向和结构的全部变异性和复杂性。
为了解决这些问题,论文提出了一个名为VGGHeads的大规模合成数据集,该数据集使用扩散模型生成,包含超过100万高分辨率图像,每张图像都详细标注了3D头部网格、面部标记和边界框。此外,论文还介绍了一个新的模型架构,能够从单个图像中一步同时检测头部并重建头部网格。通过广泛的实验评估,论文展示了在合成数据上训练的模型在真实图像上取得了强大的性能。
论文如何解决这个问题?
论文通过以下几个关键步骤解决上述问题:
-
创建大规模合成数据集(VGGHeads):
-
使用基于扩散模型的生成技术,创建了包含超过100万高分辨率图像的数据集。
-
每张图像都配有详细的3D头部网格、面部标记和边界框的注释。
-
-
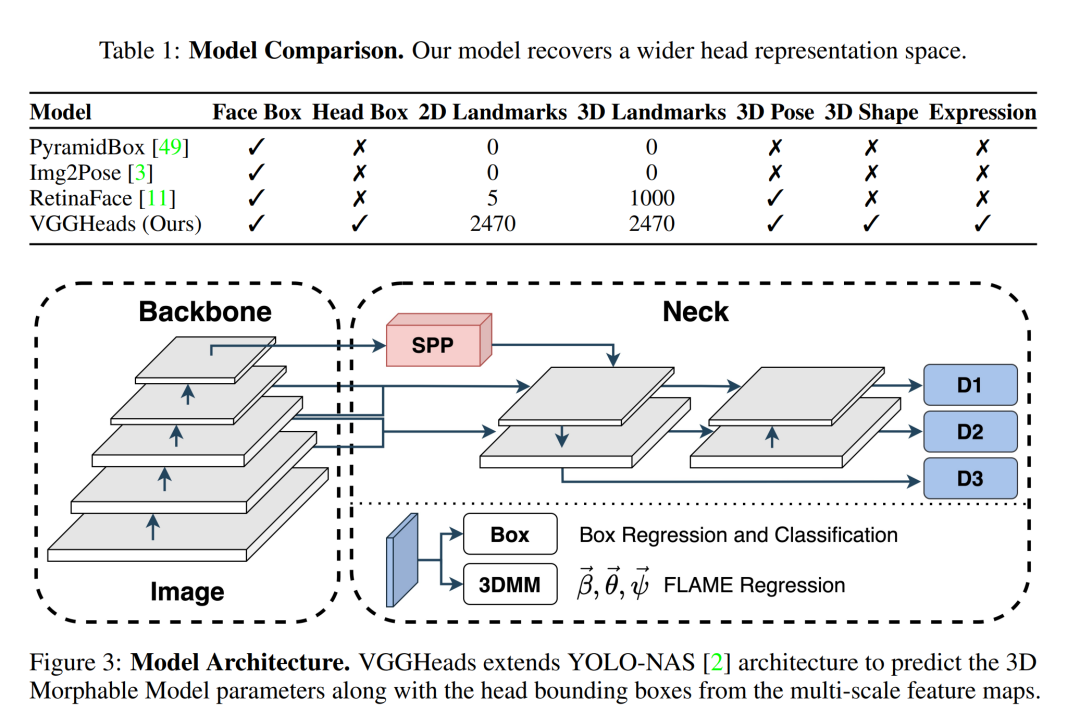
新颖的模型架构:
-
提出了一个新的模型架构,能够从单个图像中一步同时检测头部并重建头部网格。
-
该模型利用数据集中的丰富注释,同时优化边界框、3D顶点、旋转和2D标记。
-
-
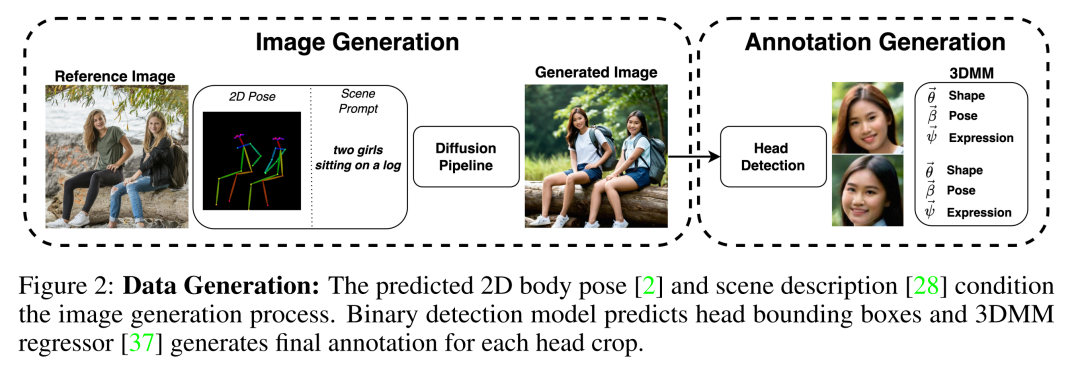
数据生成流程:
-
通过2D人体姿态和场景描述作为条件,控制图像生成过程,以模拟现实世界的场景多样性。
-
使用预训练的潜在扩散模型来生成图像,并训练一个二元头部检测模型来识别图像中的头部。
-
-
数据注释:
-
手动标记了一部分数据以训练头部检测模型,确保在不同姿态下的一致性。
-
-
数据过滤:
-
采用多阶段的过滤过程,移除可能的噪声样本和包含隐私敏感内容的样本。
-
-
安全性和隐私保护:
-
通过额外的过滤阶段,去除潜在的不安全内容(NSFW)。
-
调查了扩散模型是否会完全复制训练样本,从而可能泄露个人数据,并采取了相应的措施来缓解这一问题。
-
-
实验评估:
-
对数据集和模型进行了广泛的实验评估,包括3D头部姿态估计、3D头部对齐、面部检测等任务。
-
-
公开数据集、代码和模型:
-
为了支持进一步的研究和发展,论文提供了数据集、代码和模型的公开访问。
-
通过这些步骤,论文不仅提供了一个高质量的合成数据集,还提出了一个强大的模型,这些成果有助于推动3D头部建模和相关领域的研究,同时解决了现有真实世界数据集的局限性。
论文做了哪些实验?
论文中进行了广泛的实验评估,主要包括以下几个方面:
-
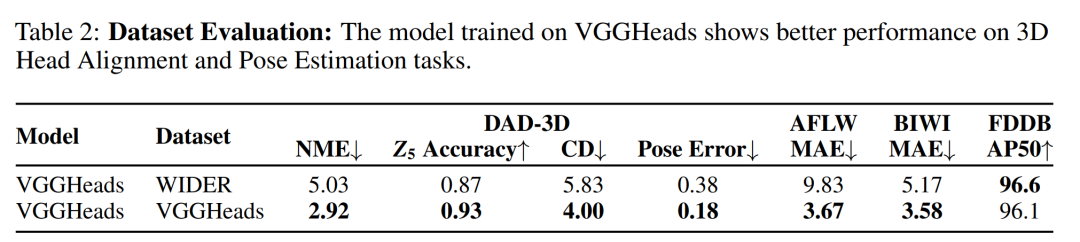
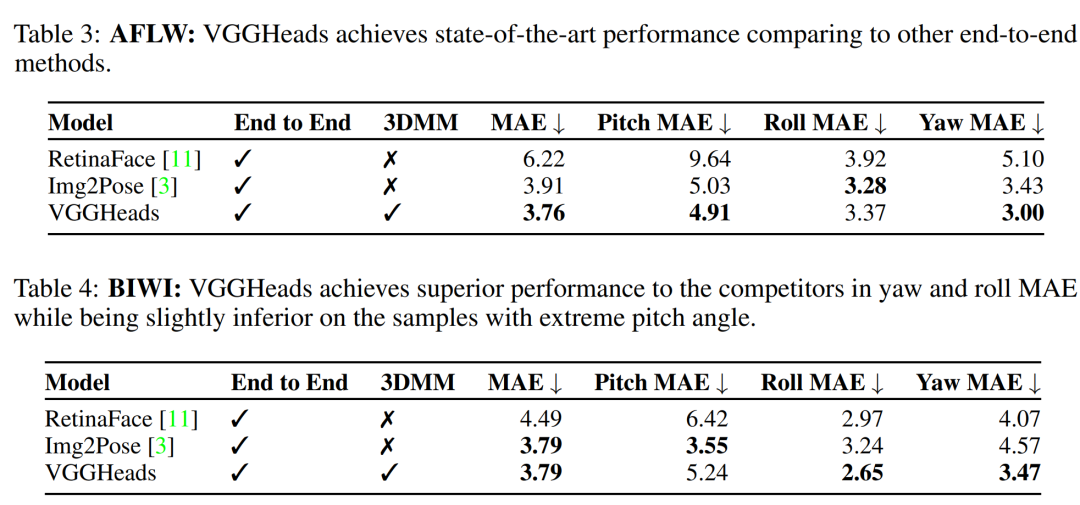
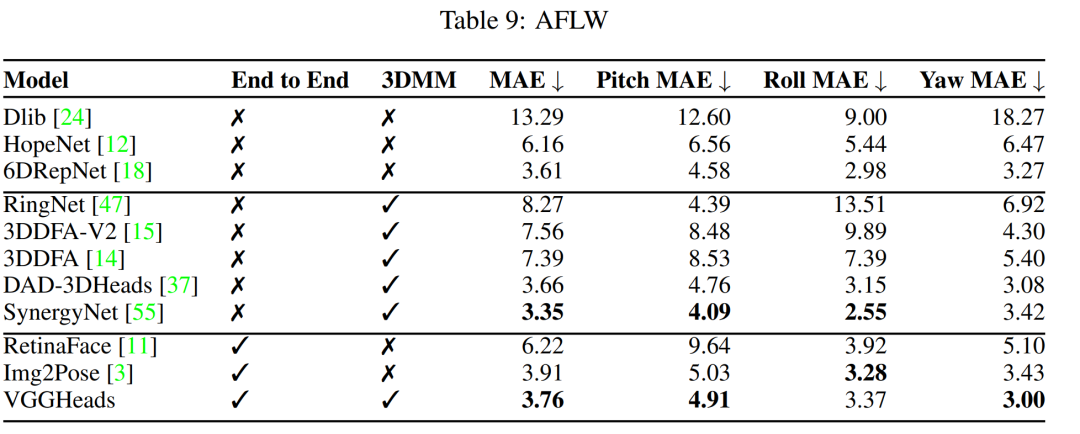
3D头部姿态估计(Head Pose Estimation):
-
在AFLW2000-3D和BIWI数据集上评估3D头部姿态估计的准确性。
-
报告了与其他端到端方法相比的性能,VGGHeads在这些数据集上的表现。
-
-
3D头部对齐(3D Head Alignment):
-
使用DAD-3DHeads基准测试,评估从图像中进行3D密集头部对齐的能力以及对极端姿态的鲁棒性。
-
比较了VGGHeads与其他方法的性能,包括在极端姿态、照明、遮挡和其他具有挑战性情况下的表现。
-
-
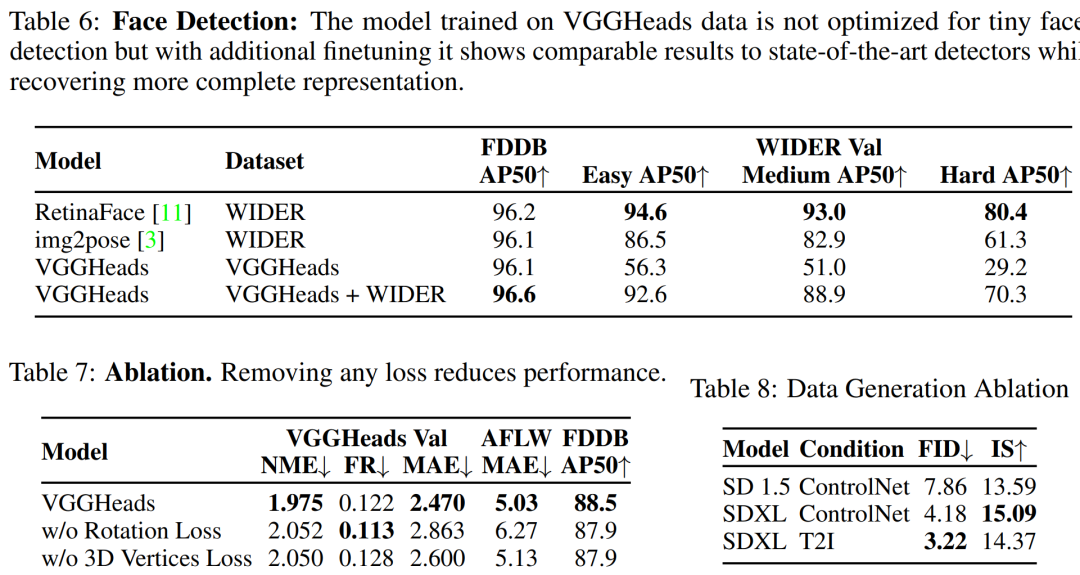
面部检测(Face Detection):
-
验证模型在不同条件下检测头部和面部的能力。
-
在FDDB和WIDER数据集上评估面部检测性能,并与其他面部检测基准进行比较。
-
-
消融研究(Ablation Study):
-
对数据生成和模型训练过程中的不同组件进行了消融研究,以验证它们对性能的影响。
-
包括对生成数据的多样性和现实性指标(如FID和Inception Score)的评估,以及对不同损失函数组件重要性的分析。
-
-
控制生成(Controllable Generation):
-
展示了如何通过条件图像生成来控制生成模型,以保持头部形状、姿态和表情。
-
-
定性结果(Qualitative Results):
-
提供了在AFLW、BIWI、DAD-3D、WIDER和FDDB基准上的定性评估结果,展示了VGGHeads在各种复杂场景中恢复3D头部模型的能力。
-
-
安全性和隐私(Safety & Privacy):
-
对潜在的不安全内容和隐私问题进行了评估,并展示了如何通过过滤和处理来减轻这些问题。
-
-
模型比较(Model Comparison):
-
与其他方法相比,VGGHeads在多个任务上表现出优越或可比的性能。
-
这些实验不仅验证了VGGHeads数据集和模型架构的有效性,还展示了它们在多种头部相关任务中的泛化能力和实用性。通过这些实验,论文证明了其方法在3D头部建模和相关领域的潜力。
论文的主要内容:
论文《VGGHeads: A Large-Scale Synthetic Dataset for 3D Human Heads》的主要内容可以概括为以下几个要点:
-
问题识别:
-
论文指出了现有真实世界数据集在3D人头检测、关键点估计和3D头部模型拟合任务中存在的偏差、隐私和伦理问题。
-
-
VGGHeads数据集:
-
介绍了VGGHeads,这是一个大规模合成数据集,包含超过100万张高分辨率图像,每张图像都有详细的3D头部网格、面部标记和边界框的注释。
-
-
数据生成方法:
-
使用潜在扩散模型生成图像,并结合2D人体姿态和场景描述作为条件,以模拟现实世界的场景多样性。
-
-
模型架构:
-
提出了一个新的模型架构,能够从单个图像中一步同时检测头部并重建头部网格,优化了边界框、3D顶点、旋转和2D标记。
-
-
实验评估:
-
通过在多个数据集上进行广泛的实验评估,证明了使用VGGHeads数据集训练的模型在3D头部姿态估计、3D头部对齐和面部检测等任务上的性能。
-
-
消融研究:
-
进行了消融研究,以展示数据生成和模型训练过程中不同组件的重要性。
-
-
安全性和隐私保护:
-
论文讨论了如何通过过滤和处理来减轻潜在的不安全内容和隐私问题。
-
-
公开资源:
-
论文提供了数据集、代码和模型的公开访问,以支持进一步的研究和发展。
-
-
结论:
-
论文得出结论,通过使用扩散模型生成的合成数据可以有效弥合合成和真实世界应用之间的差距,并促进3D头部建模及其他领域的未来发展。
-
-
伦理和影响:
-
论文强调了合成数据生成在减少隐私、伦理和安全问题方面的潜力,并促进了符合伦理标准的AI研究实践。
-
这篇论文通过其创新的数据集和模型架构,为3D人头建模领域提供了一个强大的工具,同时也为解决与真实世界数据集相关的隐私和伦理问题提供了一种可能的解决方案。




